
Ever since its first delivery in 1976 to Los Alamos National Laboratory, the CRAY-1 computer has been the industry standard in very high speed computing. Intensive research and development work in various scientific fields has been made possible because of the use of supercomputers such as the CRAY-1. Among the fields that benefit from the use of CRAY computers are: aerodynamics, meteorology, climate modelling, seismology, reservoir simulation, cryptology, nuclear fusion research, nuclear power plant safety research, circuit design, structural analysis, particle physics, astronomy, animation, and human organ simulation.
The success of the CRAY-1 within the scientific computing community can be attributed to its innovative vector architecture, dense packaging, and advanced cooling technology. The CRAY-1 design employed many state of the art architectural features such as:
The vector architecture introduced, at that time, a new era in high speed computing. The well balanced [1] and compact [2] design enhanced the performance of vector as well as scalar application codes.
There are many references available that discuss in great detail the architecture, physical characteristics and usage of the CRAY-1 computer [3][4][5].
In 1979, while Seymour Cray was leading the development of the CRAY-2, a separate effort, led by Steve Chen, and under the direction of Les Davis, was initiated within Cray Research to design a machine more powerful than the CRAY-1.
Several important decisions regarding design strategy were made.
To shorten the time for circuit design, the same 16-gate ECL gate arrays to be used in the CRAY-2 were chosen. However, other than components, there was virtually no similarity between the two design efforts.
Since the design requirements of the two projects were totally different, new electronic design rules needed to be defined.
To increase the packaging density and to shorten machine cycle time, new packaging techniques were employed and stringent design rules were used throughout the design process. For the first time at Cray Research, design rules and module temperatures were checked by CAD/CAM support software.
We had the option of using an exotic cooling technology to have denser packaging and hence a shorter clock period. Since we were experimenting with a new architecture and new component technology, a conservative decision was made to use an enhanced version of the CRAY-1 cooling technique.
We also had a choice between super vector speed and faster scalar performance. It was conceivable that adding more vector units would double or even quadruple vector speed for long vectors. Although it was necessary to improve vector speed, it was more important to improve the scalar speed and not to compromise the system throughput capability of the machine. A deliberate decision was made to pursue a multiprocessor design instead of multiple vector units. Vector performance was increased, nevertheless, through other innovative means.
It was also decided that the development would be done within a small design team. Including logic designers, electronic, mechanical, CAD, software and application engineers, the entire design team had less than twenty people. The design and checkout of the prototype had to be completed in a very short time frame before the market window was filled by other vendors.
It was less than three years from the inception or the project in mid 1979 to the completion of the checkout of the prototype CRAY XMP-2 in April, 1982. It proved once again that innovation and productivity are possible from a small team.
Shortly after the prototype checkout, the design of a four processor model began. In less than two years, the development, artwork, manufacture and checkout were completed. The four processor version, CRAY XMP-4, was demonstrated internally the end of April, 1984.
A parallel effort was initiated by the continuation engineering team to employ the central processing unit (CPU) of the XMP, combined with the relatively inexpensive MOS memory technology, in developing a single processor model, the CRAY XMP-1. This project was completed by the end of 1983. However, in anticipation of market changes, this model was not announced until mid 1984, along with the four processor model.
Since overall performance of a machine can only be as fast as its slowest component[6], machine speed is much more than just MFLOPS (Millions of FLoating point OPerations per Second). High execution rates for certain special classes of codes (such as loops with long vectors) do not always lead to greater system throughput. In reality, large scale scientific problems benefit most from a balanced system design [7][8].
In most machines, I/O speed is the slowest component. To bridge the memory bandwidth difference between the mainframe and the slower I/O devices an optional Solid-state Storage Device (SSD) was designed by the continuation engineering team. The demonstrated balanced approach to system performance is one strength of Cray Research that people interested in MFLOPS rates often overlook.
Housed inside the same physical chassis of the CRAY-1, the XMP mainframe has many distinctive features that again advance the state of the art in high speed computing [15]. The CRAY XMP Series of computers is a range of nine compatible supercomputer models based on the XMP CPU. Configurations are available with one, two or four identical processors, and use two different memory technologies, either bipolar ECL or static MOS. The CRAY XMP Series is software upward compatible with earlier CRAY-1 systems and is supplemented by a significantly enhanced I/O capability. Figure 1 gives the overall system organization.
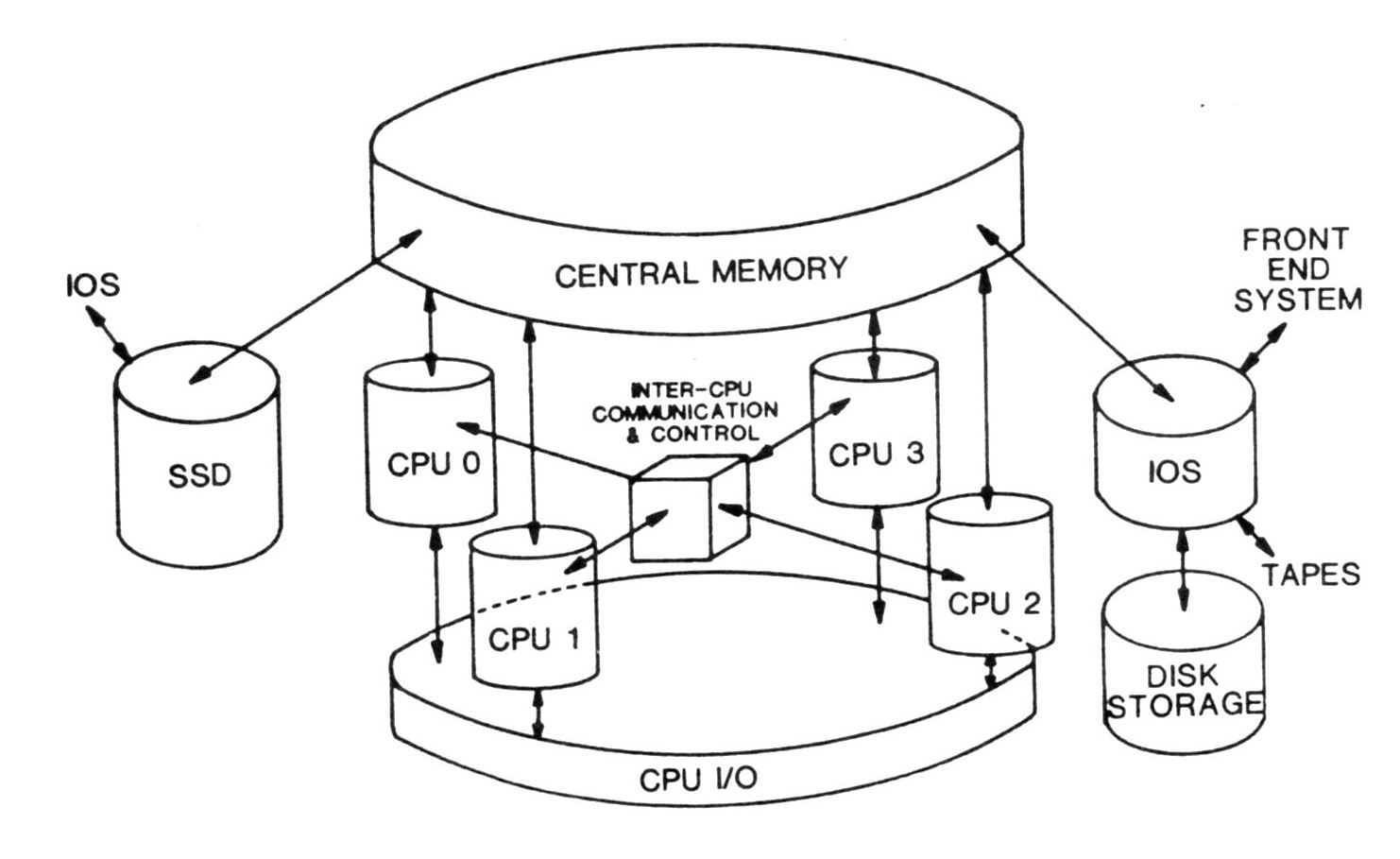
Although built upon the basic architecture of the CRAY-1, see figure 2, the CRAY XMP processor is totally redesigned. All processors share a central memory of up to 16 million (64-bit) words, organized in up to 64 interleaved memory banks. All banks can be accessed independently and in parallel during each machine clock period. Each processor has four parallel memory ports (four times that of the CRAY-1) connected to the central memory: two for memory loads, one for memory stores and one for independent I/O operations.
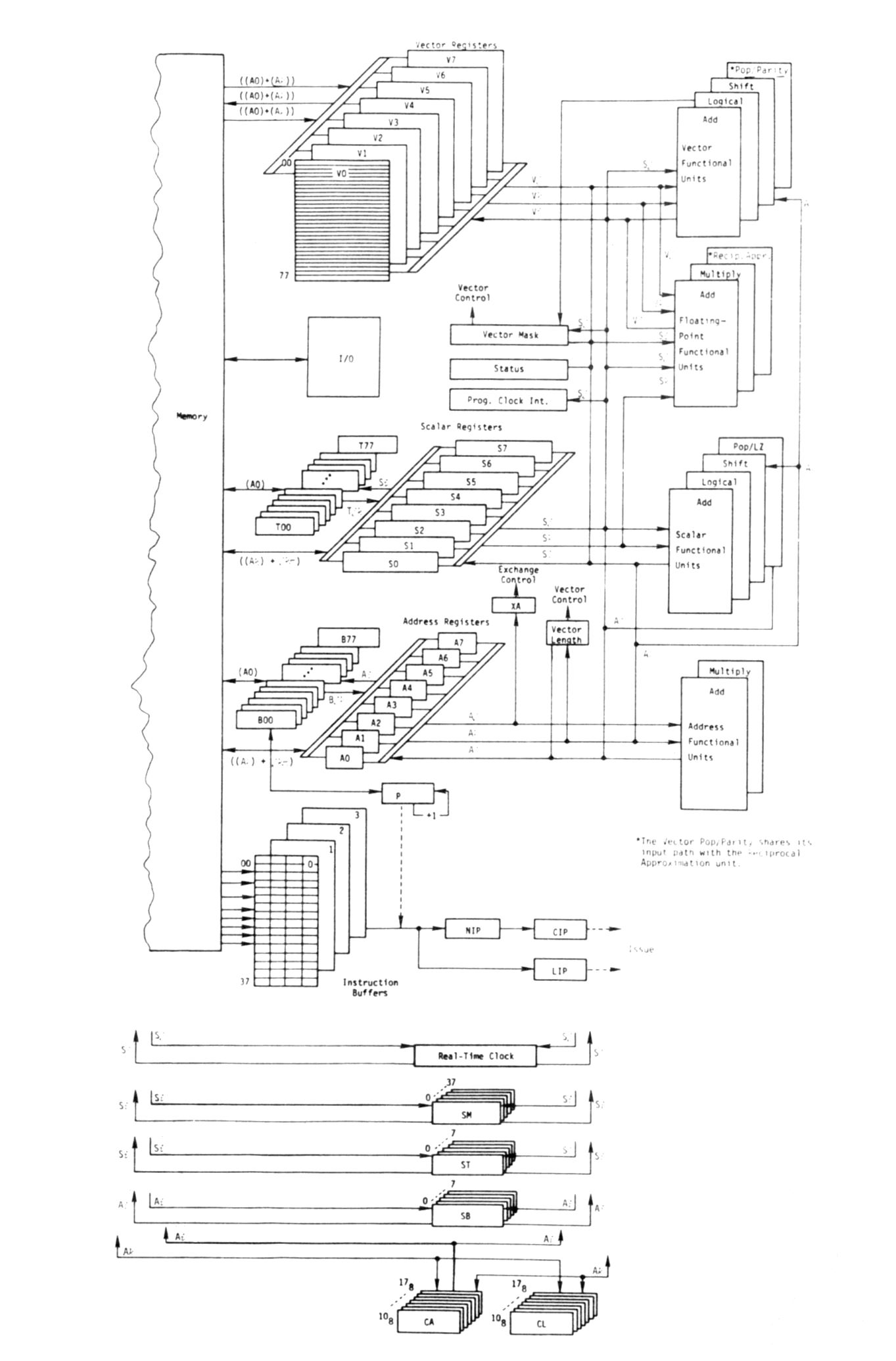
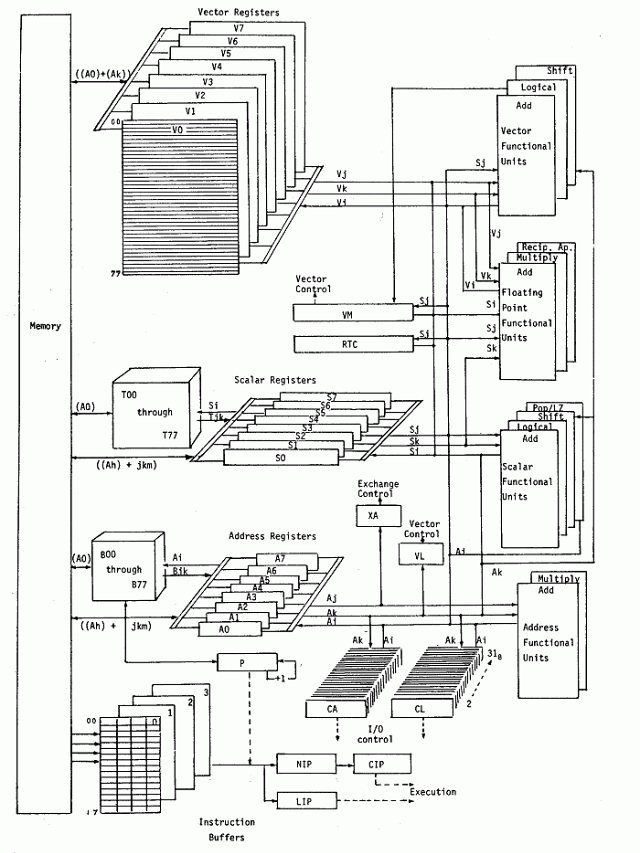
The multiport memory has built-in conflict resolution hardware to minimize access delay and to maintain the integrity of all memory references from different ports to the same bank at the same time. The multiport memory design, coupled with a shorter memory cycle time, provides a high-performance memory organization with up to 16 times the memory bandwidth of a CRAY-1. The improved memory bandwidth balances the multiple-pipelined computing power of the CPU and the data streaming ability of the memory. For each processor, this capability coupled with the reduced clock period gives a performance speedup over the CRAY-1 of up to 4.
All processors are controlled synchronously by a central clock with a cycle time of 9.5 ns (vs. 12.5 ns of CRAY-1). I/O ports are also shared by all the processors. I/O can be initiated by any processor and any processor can field any I/O interrupt. Whenever a processor is in the operating system, for any reason, that processor will handle all I/O interrupts. If no processor is in the operating system, I/O interrupts are given to the initiating processor.
The scalar performance of each processor is improved through faster machine clock, shorter memory access time, larger instruction buffers (twice that of the CRAY-1 per processor), multiple data paths and, above all, multiple processors.
The vector performance of each processor is improved through faster machine clock, parallel memory ports and an hardware automatic flexible chaining feature. The XMP design allows simultaneous memory fetches, a sequence of computations and memory store in a series of related vector operations.
Figure 3 illustrates the benefits of these features for a common vector computation in linear algebra. On the CRAY-1, this computation takes three chimes [3]. A chime is a chained operation time. The chimes consist of (load), (load,*,+), and (store). The single port to memory on the CRAY-1 prevents any further overlap of operations. The compiler must insure that the multiply and add instructions are issued at the proper time to catch the chain slot times for the computational chime. Each of the operations proceeds at a rate dictated by the CRAY-1 clock period.
CHAINING WITH MULTIPLE MEMORY PORTS
A = B + s*D
CRAY-1/S CRAY XMP
load B !-----! !-----!
load D !-----! !-----!
* !-----! !-----!
+ !-----! !-----!
store A !-----! !-----!
On the CRAY XMP, this computation takes only one chime. All operations are pipelined and proceed at a faster clock period rate. Additionally, the compiler has greater freedom in the scheduling of these and other supporting instructions since there is no fixed chain slot time. The elimination of fixed chain slot time and concurrent bidirectional memory access make the machine more amenable to the Fortran environment than the CRAY-1. As a result, the processor design provides higher speed vector processing capability for both long and short loops, characterized by heavy memory-to-memory vector operations.
There are also new features that support vector indirect addressing and vector conditional executions. The hardware gather/scatter unit and hardware support for compress/expand operations allow the vectorization of sparse matrix computations and certain Fortran loops with IF statements.
A unique distinction of the CRAY systems is that the vector and scalar units and controls are so intimately integrated that, physically, there is no clear scalar nor vector processor sections. This design philosophy requires tighter packaging, and allows for shorter vector pipe startup time and for faster data flow between scalar and vector units as required in the execution of typical user codes with interspersed scalar and vector code segments.
The identical processors are able to operate independently of one another and may execute different jobs simultaneously. For the processors to communicate with one another efficiently in a shared central memory environment, new hardware mechanisms are provided for interprocessor communications.
In the multiprocessor XMPs communication among processors is accomplished by clusters. Each cluster consists of eight 24-bit shared B registers, eight 64-bit shared T registers and thirty-two 1-bit semaphore registers. On the two processor XMP there are three of these clusters and on the four processor XMP there are five clusters. One cluster is typically reserved for operating system use and the others are available for user jobs.
The assignment of clusters is a function of the operating system. Any or none of the clusters may be assigned to a processor. However, only one cluster may be assigned to a processor at a time. When two or more processors are assigned to the same cluster, the cluster may be used for communication among those processors. The single processor XMP does not have clusters but the functionality can be simulated in memory for multitasking communication. On the multiprocessors, hardware arbitrates the access to a cluster during each machine cycle. When there is contention for the cluster, access is rotated among the contending processors on successive cycles.
Cluster Operations
This last operation, the wait and set function on semaphore registers is a mechanism which includes hardware interlock. This interlock prevents a simultaneous wait and set operation on the same semaphore register from more than one processor. This basic control operation can be used to implement any of the other common software synchronization mechanisms.
This busy wait operation has two significant advantages over most other hardware interprocessor exclusive access controls, such as, test and set, or compare and swap. First, it does not reference memory. Spin wait sampling of the same location in memory is avoided and hence disruption of memory accesses by other processors is eliminated. Second, the hardware can detect whether a processor is waiting. As a consequence the waiting processor can be selected at the time of interruption to do other useful work such as processing I/O interrupts. Furthermore, a primary deadlock condition is detectable by the hardware. When all processors which are assigned to a particular cluster are waiting on semaphores, that group of processors is deadlocked and the hardware issues a deadlock interrupt to each of them. The deadlock can then be resolved through the governing system software. This is useful not only in resolving a true deadlock situation but also in scheduling useful work. For example, when there are more tasks to be executed for a user code then there are physical processors, other tasks for that user code can be put into execution when the deadlock interrupt is detected.
The interprocessor communication mechanism allows the processors to send and acknowledge messages, and to synchronize activities in a timely way. The efficient mechanism enables the multiprocessors to execute the tasks of a single user code simultaneously in a coordinated manner (multitasking). This added dimension of parallel processing is at the Fortran outer loop level, on top of the vector processing at the inner loop level. The ability to simultaneously exploit these two levels of parallelism is unique to the CRAY systems. Figure 4 clarifies this multi-level parallelism.
The computational power of the XMP Series is complemented by powerful I/O capabilities. For problems requiring extensive data space and data movement, the I/O structure of the XMP ensures that computing power is not limited by I/O capability.
The I/O Subsystem (IOS) consists of two to four processors (IOPs). The IOS acts as a concentrator and data distribution point for the CRAY XMP mainframe. The IOS communicates with a variety of front-end computer systems (one to seven) and with peripherals such as disk units and magnetic tape units. A direct access path is also provided between the IOS and the SSD.
Associated with the IOS is a large buffer storage space for data transfer and for temporary scratch files. The IOS Buffer Memory is a solid-state storage device, using the same technology as the SSD, is accessible to all the I/O processors in the IOS and is available in 8, 32, or 64 Mbytes capacities. All IOPs are connected to the Buffer Memory through 100 Mbytes/sec ports. The Buffer Memory has single-bit error correction and double-bit error detection (SECDED) logic, and is field upgradeable. It provides a large I/O buffer area between the mainframe and the peripherals (up to one Mbytes each) and allows user files to be Buffer Memory resident, thus contributing to faster and more efficient data access and processing by the CPU's.
In the IOS, each high speed channel (HISP) for streaming data to central memory has a burst transfer rate of 100 Mbytes/sec. With software overhead, the sustained rate is 68 Mbytes/sec. One bi-directional channel is standard on all systems, and a second is optional.
The IOS can support parallel disk streaming, software disk striping, a direct path between disk and the SSD without interference to the mainframe, I/O buffering for disk resident and Buffer Memory resident files, and online tapes as well as front-end system communication.
The SSD is an optional, large, very fast, CPU-driven random access secondary storage device designed as an integral part of the mainframe. It can be used like a disk to store non-permanent files.
The SSD has a range of storage capacities from 256 Mbytes to 1 Gbytes. Like the central memory, it has SECDED logic for error checking. The very high speed channel (VHISP) between the SSD and the central memory is capable of transfer rate of 1 Gbytes/sec, 100 times that of Cray's fastest disk, the DD-49. On the XMP-4, two VHISP channels can double this bandwidth. A transfer rate of 1.8 Gbytes/sec has been measured on that model. For example, a data block of 16 Mbytes can be transferred in 8.89 ms. This fast transfer rate, coupled with a short access time (less than 0.4 ms for a single request, more than 40 times faster than that of a DD-49, and 25 us for a list of requests) offer an attractive alternative to a large expensive bipolar central memory. The SSD configuration is field upgradeable.
The SSD has four additional 100 Mbytes/sec channels that can be linked to the I/O subsystem. In all, the SSD can be used as a fast-access user device for large pre-staged or intermediate files generated and manipulated repetitively by user programs. Its speed versus disk I/O can significantly affect the performance of large, I/O limited, scientific application codes. See figure 5.
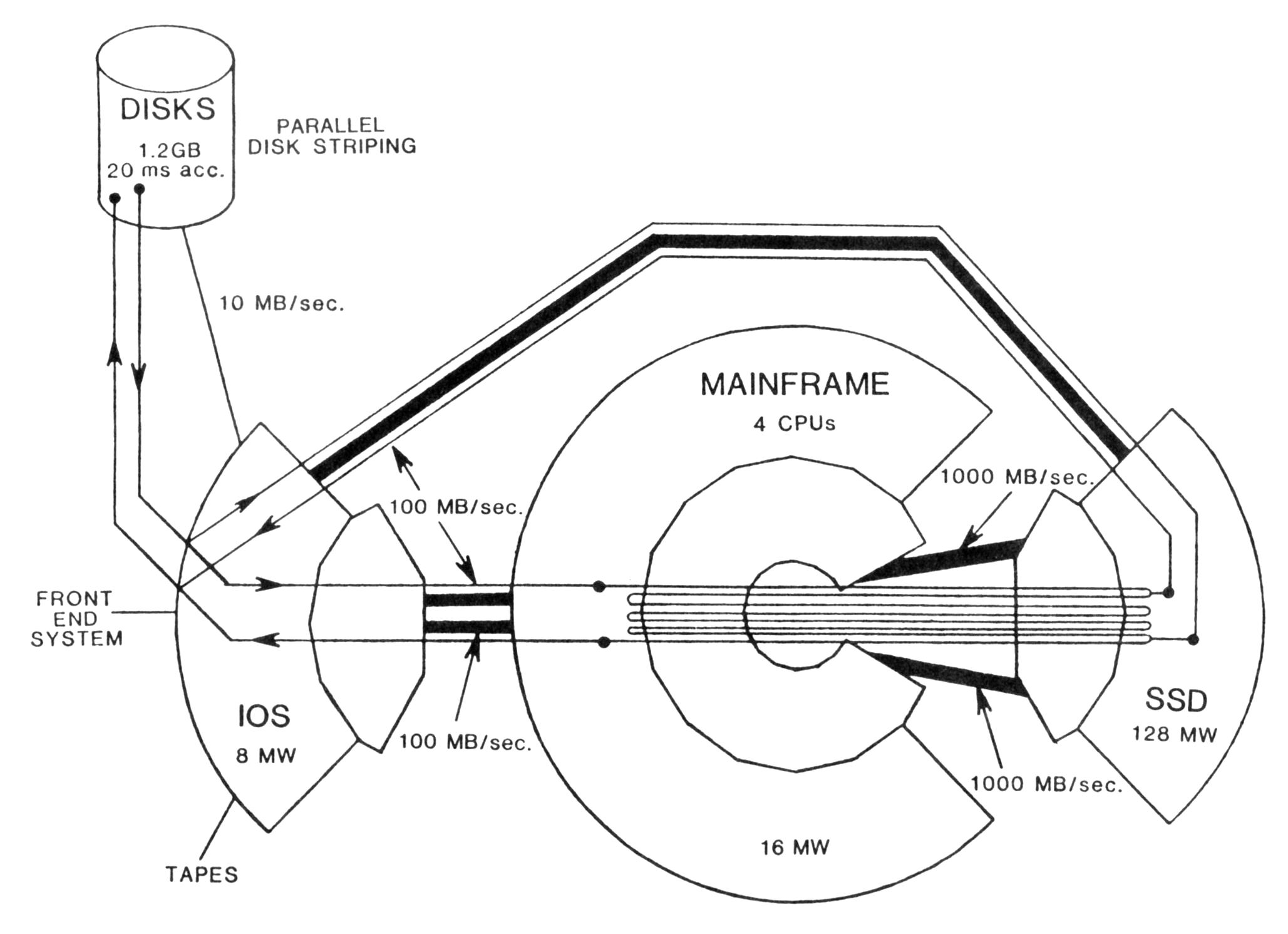
The SSD can also be used by the system for job swapping space and temporary storage of system programs, thus improving system performance.
Furthermore, the reduction of I/O time makes multiprocessing of large 3-D simulations attractive. High performance I/O and multitasking enable the user to explore new application algorithms for solving bigger and more sophisticated problems in science and engineering which could not be attempted before.
Traditionally, disk speed has been the limiting factor for large I/O bound scientific problems. To complement and balance the CRAY XMP computing power, the CRAY DD-49 disk is available as a high density, dual port magnetic storage device, capable of reading and writing data at a burst rate of 12 Mbytes/sec. Each disk cabinet holds up to 1.2 Gbytes of formatted data on twin spindles. A sustained transfer rate of 10 Mbytes/sec is achievable, 2.5 times that of its predecessor, the DD-29.
Up to 32 DD-49 disks can be connected to an IOS for 38.4 Gbytes of disk storage. When combined with the disk striping and buffering capability of the IOS, these disks provide the XMP system with unsurpassed disk performance.
The CRAY XMP mainframe consists of 6 to 12 vertical columns arranged in an arc identical to that of the CRAY-1. The power required for a fully populated mainframe is about 30% higher than that of the CRAY-1. Accordingly, the machine requires 30% more cooling capacity. This is achieved through several enhancements. For example, a heat sink pad is added underneath each chip which attributes to a much better cooling effect for each individual chip. Also the use of drilled aluminium coldbar instead of a cast coldbar with internal tubing increases the efficiency due to less conductor interfaces.
One distinctive characteristic of the XMP lies in its packaging technology. The use of 16-gate gate arrays, eight times the integration of the 2-gate chips used in the CRAY-1, has great implications for packaging, and a faster machine cycle time. The 16-gate gate array may consume four to five times the power of a 2-gate chip and thus creates heat dissipation problems if high wattage chips are concentrated in one locality. But, in order to shorten the signal travel time on the circuit board foil, chips can not be placed too far apart either. To achieve a faster clock rate, stringent design rules also limit the number of fan-outs and load clustering. These difficult factors make chip placement and PC routing extremely challenging.
On the CRAY-1, two standard 6in × 8in circuit boards are mounted on two sides of a copper plate. The whole unit is called a module. Inter-module communication is done through twisted wires which are 3 to 4 feet in length. In order to shorten the signal traveling time, a tighter packaging technique is necessary. On the XMP, where a double module is used, two CRAY-1 like modules are sandwiched together. All four circuit boards may communicate through fixed locations via jumpers.
With 200 to 300 chips per module and thousands of latch-to-latch paths to check, the enforcement of design rules is no longer humanly possible without automation aids. The CAD support software checked and enforced design rules at every stage of the design process. Functional unit level logic simulation reduced the number of design errors before the machine was physically built. To keep the junction temperature of the chip to below 85C, power rules governing chip placement were also automated. The CAD effort smoothed the machine design process. This is of particular historical importance to Cray Research. The XMP project marks the first time this supercomputer manufacturer directly used a computer to design another. The complexity of the task required the use of a current generation of supercomputer to design the next generation.
The CRAY-1 hardware was introduced in 1976 with only a minimum complement of available software. The early customers were sophisticated computer users willing to develop much of their own software to gain access to the performance of the CRAY-1. As the customer base broadened, the software available also grew. When the CRAY-XMP was introduced in 1982, a broad selection of software existed. The CRAY-XMP is upward compatible with its predecessor, so that software developed for the CRAY-1 migrated easily to the new hardware line. Since that time software development has continued with emphasis on optimization and the new capabilities of the XMPs.
The Cray Operating System (COS) is a mature system which executes on the full line of the earlier CRAY-1's and the current CRAY XMPs. This efficient operating system has both multiprogramming batch job management and interactive timesharing capabilities. Both batch and interactive jobs have access to the same data files, interface with the outside world via stations on front-end processors, and use a common job control language.
COS supports up to 255 active user programs. These can be interactive jobs, batch jobs, or tasks of user multitasking jobs. Multitasking is invoked explicitly by user programs that create tasks to be run in parallel with other tasks within the job. Jobs compete for memory based on a priority and a dynamic aging scheduling system. Once in memory, jobs and tasks within jobs are scheduled together in a typical multiprogramming environment. A processor in a multiprocessor system is assigned on a first available basis to any of the jobs or tasks as they become ready on a round robin execution queue.
Cray Research and several major computer vendors have developed station software so that the familiar machine at the customer's site can be used as a front-end to the CRAY XMP. This enables the editing and data processing capabilities of the front-end system to be used to prepare and submit the jobs to the CRAY. This achieves a balanced separation of functions with the front-end handling the interfacing with the end user and the CRAY XMP doing the computationally intensive work. Interactive stations are available for several different manufacture's machines, and link the familiar terminal environments through to the interactive capabilities of COS on the CRAY XMP.
Much of the data used by jobs is staged to the CRAY XMP via the front-end stations. However, the low bandwidth of these front-end systems often limits the performance levels. The dataset management capability of COS is designed to support the full high-speed computational power of the CRAY XMP. The dataset manager provides efficient and flexible creation, use, and maintenance of temporary and permanent files. Although user programs can easily interface with the dataset manager, simple JCL directives allow programs to use different files without program modifications. The default allocation of files to physical disks can be overridden by JCL statements. This allows easy use of (physical or logical) devices of higher bandwidth at run time.
Multiple disks may be grouped together by COS using a software technique called striping (interleaving) where successive data blocks are distributed among the disks, effectively multiplying the bandwidth by the number of disks in the group. The performance improvement is obtained by changes at the JCL level and need not affect the user program. See figure 6.
Furthermore, when a job uses files each of which is allocated on a different physical disk, access may proceed without contention. This is called disk streaming.
With two disk I/O processors (DIOPs) in the I/O subsystem, COS can sustain streaming of up to twelve DD-49s at a rate of 9 Mbytes/sec each. For file transfers involving multiple disks, COS can deliver an aggregate transfer rate of up to 108 Mbytes/sec.
Similar transfer rates can be achieved for individual files which are stored in the IOS's Buffer Memory. Through the high speed channel between the IOS and the SSD, files may be copied directly between disks and the SSD without involving the mainframe. This backdoor approach totally eliminates central memory contention and the use of central memory space due to I/O. The staging of the data can be done either at the user program level or can be anticipated with a JCL level utility command.
A task is a unit of computation that can be scheduled. The main program is a task. Multitasking occurs when additional tasks belonging to the same job are created.
Multitasking is implemented at the FORTRAN level, where the user can write CALL statements to ask for multitasking functions. Many of the functions provided are similar to those found in the Industrial Real Time FORTRAN Standard [11]. The key multitasking routines are shown in figure 7, and provide the basic capabilities needed for task initiation, synchronization, and mutual exclusion.
Tasks are initiated with the TSKSTART statement by supplying a subroutine name and any necessary arguments. The TSKWAIT statement is used to wait on the completion of a generated task. As tasks execute concurrently, they may need to use quantities produced by other tasks. To ensure that these quantities are computed before they are used, the producing task may use the EVPOST routine to signal other tasks to proceed. Consuming tasks use the EVWAIT routine to listen for this signal. The EVCLEAR routine clears the signal.
Critical region protection is provided by the LOCKON and LOCKOFF routines. A task enters a critical region by turning a lock on, and exits by turning the lock off. Tasks which attempt to enter an occupied critical region wait until the lock is turned off.
The basic property of codes which can be multitasked is independence. This independence allows a partitioning of the program into tasks which may be executed in any order, or concurrently. Independence may be found at a low level in the iterations of a loop, or at a high level along geometric or other problem attributes which involve several subroutines. In general, the higher the level of independence exploited, the higher the performance speedup. Independence analysis considerations are described in [[9][16].
TASK CONTROL ------------------------------------------------------- CALL TSKSTART ( TASKID, SUBNAME, ARGS ) creates a task with identification TASKID and entry point SUBNAME ( ARGS ), builds a stack, and enables the task for processor scheduling. CALL TSKWAIT ( TASKID ) suspends the calling task until the task with identification TASKID has completed. EVENT CONTROL --------------------------------------------------------- CALL EVPOST ( EVENT ) changes the status of the event variable, EVENT, to 'posted'. CALL EVWAIT ( EVENT ) suspends the calling task until the status of the event variable, EVENT, is 'posted'. CALL EVCLEAR ( EVENT ) changes the status of the event variable, EVENT, to 'cleared' . ----------------------------------------------------------- LOCK CONTROL CALL LOCKON ( LOCK ) suspends the calling task until the status of the lock variable, LOCK, is 'unlocked', then changes the status to 'locked'. CALL LOCKOFF ( LOCK ) changes the status of the lock variable, LOCK, to 'unlocked'.
The architecture is ideally suited to the FORTRAN DO loop structure. The Cray Fortran Compiler (CFT) automatically exploits the parallelism in this construct. No special syntax or subroutine calls are needed. This natural fit of the Cray vector architecture and the vectorizing compiler to the FORTRAN DO loop structure means that most codes can make use of the vector capabilities without reprogramming.
hardware features allows CFT to vectorize two classes of code which previously were performed in scalar mode. These new features are a gather/scatter function and an index compression function. These functions are used by the compiler to vectorize codes which do not have a constant memory reference stride.
The first class involves indirect addressing, for example,
DO 1 I =1, N
A(J(I)) = B(K(I)) + ...
1 CONTINUE
The storing of array 'A' indirectly addressed by J(I) is called a scatter operation and the corresponding loading of array 'B' indirectly addressed by K(I) is a gather operation. These functions appear in table look-up algorithms, translation codes, and in sparse matrix operations. Previously, the CFT compiler would identify the scatter/gather operations and generate calls to special optimized subroutines. With the hardware features, the scatter/gather functions can be included inline and be involved in the local code optimization.
The second class of code involves DO loops which contain conditional executions. For example,
DO 1 I =1, N
IF (A(I) .NE. 0.) B(I) = B(I) / A(I)
1 CONTINUE
Once again there is no constant stride in the reference pattern. The CFT compiler optimized for previous systems would generate code which referenced and computed with all array elements but only changed the ones selected by the 'TRUE' condition.
This strategy has two drawbacks. First, since this vector mode implementation operates on all elements, scalar code may be faster when the selection is very sparse. Second, since the arithmetic is done on all elements, errors can occur for elements which should not have been selected; i.e., the condition may protect the code from dividing by zero.
CFT treats this kind of vector merge as an unsafe optimization.
On the XMP-4 an index compression operation has been implemented in the hardware which allows the list of DO loop index values to be compressed into a dense array containing only the values selected under the condition. The scatter and gather functions can then be used to make the storage references related to these index values. The same number of elements is involved as would be in the scalar version of the loop but the loop now executes at vector speed. Also, only the elements selected are used for the arithmetic so no false errors can occur. CFT optimizes DO loops containing this type of conditional code automatically.
To facilitate multitasking, several major changes were made to CFT. Local variables of a subroutine are allocated on a stack. Related to this mechanism, the calling sequence is also amended. These changes allow CFT to produce re-entrant object code, a first step toward multitasking.
In a multitasking environment, there is a need for a new kind of data scope, namely, at the task level. This scope allows data elements to be shared among the subroutines of a task, but to be private to each task for its duration. This is particularly useful if the same routine is used by different tasks. In order to support this new scope, a new COMMON statement called 'TASK COMMON' is provided in the CRAY FORTRAN language.
There arc several dimensions along which the CRAY XMP may be measured. The following sections investigate single and multiple processor, as well as I/O, performance.
Many application codes require only the performance of a single, fast CPU. The architectural features of each XMP processor, as mentioned in previous sections, enable improved performance over the CRAY-1 either in FORTRAN or in Cray Assembly Language (CAL).
Examples of simple loops, and scientific FORTRAN and CAL library routines illustrate the speedups obtained in computationally intensive applications.
The single XMP processor performance is demonstrated by comparing it with the CRAY-1 for several benchmarks sets. The first set consists of FORTRAN vector loops as shown in figure 7. The relative performance varies as a function of vector length from a typical speedup of 1.5 for short vectors (vector length = 8), to 2.5 speedup for medium vector length of 128, to 3.0 speedup for long vectors of length 1024. The best speedup occurs for the SAXPY operation (A=B+s*D) which produces a speedup of 4.0.
(1-CPU X)/1S SPEEDUP
SHORT MEDIUM LONG
VECTOR VECTOR VECTOR
(VL=8) (VL=128) (VL=1024)
A = B 1.1 1.8 2.1
A= B+C 1.2 2.2 2.7
A= B*C 1.5 2.6 3.3
A= B/C 1.5 1.9 2.0
A= B+C+D 1.5 2.7 3.2
A= B+C*D 1.4 2.9 3.6
A= B+s*D 1.3 3.0 4.0
A= B+C+D+E 1.3 2.3 2.7
A= B+C+D*E 1.6 2.5 2.9
A= B*C+D*E 1.3 2.5 3.1
A= B+C*D+E*F 1.5 2.1 2.2
--- --- ---
typical 1.5 2.5 3.0
(Unit based on compiler generated
code running on CRAY-1)
The XMP four processor system introduces new machine instructions and hardware support for executing gather and scatter operations in vector mode. These operations chain together with arithmetic and. other memory instructions. The compiler is able to detect these constructs and generate vector code automatically. On the CRAY-1 and early CRAY XMP two processor systems, gather and scatter operations execute only in pseudo vector mode; for example, gathers are performed in a scalar fashion into a vector register. Figure 9 illustrates the performance speedup of the following sparse SAXPY, or SPAXPY, loop on a single XMP-4 processor versus the CRAY-1.
DO 1 I =1, N
A(I(J)) = A(I(J)) + S*B(J)
1 CONTINUE
For this example, a compiler directive is needed to indicate that the subscripts are distinct and hence that the loop is indeed vectorizable.
(1-CPU XMP-4)/CRAY-1 SPEEDUP
SHORT MEDIUM LONG
VECTOR VECTOR VECTOR
(N =8) (N =128) (N =1024)
6.7 15.6 15.7
(Unit based on compiler generated code running on CRAY-1)
The second set of benchmarks consists of assembly language scientific library routines. See figure 10. The vector length for the relative performance shown is 128 for the matrix operations, 8192 for the FFTs, and 4096 for the others. The code in each example is tuned for each machine. The speedups vary from 1.33, for those routines which use algorithms utilizing only one memory port, to 4.04 for the SAXPY operation. Other cases perform matrix computations, and Fast Fourier Transforms. Noteworthy are the first order linear recurrence routines for which new vector algorithms have been designed. Compared to the old method on the CRAY-1 the new versions show very impressive speedups: 5.93 for the full solution, and 7.32 if only the last value is required. The new algorithm may also be used on the CRAY-1 and a fair comparison shows speedups (in parentheses) in the expected range.
The final set of benchmarks consists of FORTRAN library routines taken from LINPACK and EISPACK. See figure 11. The routines from LINPACK solve a general system of equations, while the EISPACK routines solve eigenvalue problems. The order of the matrices involved is 400. The performance speedup of the single XMP processor over the CRAY-1 varies from 2.80 to 3.27 for these examples.
CODE (1-CPU XMP)/CRAY-1 SPEEDUP SSUM 1.36 SOOT 2.26 SAXPY 4.04 FOLR(*) 5.93 (3.40) FOLRN(*) 7.32 (1.94) GATHER 2.55 SCATTER 2.48 MXM 1.33 MXMA 1.42 MINV 2.18 CFFT2 2.16 CRFFT2 2.12 RCFFT2 2.11 (*) New vector algorithms used on XMP only; the number in ( ) indicates the speedup when vector algorithms are applied to both XMP and CRAY-1.
(1-CPU XMP)/CRAY-1
CODE SPEEDUP FACTOR
SGEFA 2.77
SGECO 2.75
SGESL 2.84
SGEDI 2.63
TRED2 3.08
TRED1 2.80
TRBAK1 3.27
I/O performance is a good indication of the versatility of a machine in a real application environment. Performance gains on the XMP are achieved by addressing the I/O requirements in application codes. By using disk striping, Buffer Memory or SSD, several examples show significant speedups in this often neglected area.
Data transfer to or from disk can often be a bottleneck in out of core problems, resulting in diminished processor utilization and excessive I/O wait times. The limitation imposed by the transfer rate of a single disk is significantly enhanced through the disk striping capability in CRAY's IOS software, as described in a previous section.
Figure 12 illustrates the I/O times for an oil reservoir benchmark utilizing striped disks. Several runs were made, each with a different number of physical disks comprising the logical disk group.
Number of disks I/O time in stripe group (sec) Speedup 1 34.9 1.00 2 17.6 1.98 3 13.3 2.62
The Solid-state Storage Device is a new secondary storage device that addresses the I/O needs of large scale scientific problems. An example of the I/O speedup attributed to the use of SSD is provided by a 3-dimensional seismic migration code, 3DMIGR. This code is used to determine the underground structure of the earth in oil exploration [10].
A model problem involving 200 × 200 traces, with 1024 time samples per trace, and 1000 depth levels is quite I/O bound when intermediate files reside on disk. The total computational requirement of the job is 1.5E12 floating point operations, while a total of 4.0E10 words are transferred to and from disk during execution. The total execution time for the code when run on one CPU with DD-29 disks is 23.8 hours. See figure 13. By assigning the intermediate files to the SSD, the I/O wait time is virtually eliminated. The job becomes computationally bound, and the total execution time for one CPU with SSD is 3.58 hours, a speedup or 6.6. This example is used again in the next chapter where multitasking will further improve this speedup.
3-D MIGRATION CODE (1-CPU)
EXECUTION TIME SPEEDUP
with DISK with SSD
23.8 hr 3.58hr 6.6
The multiple processors of the XMP system are available to support the computational needs of users in two ways for increased throughput. The independence of user jobs is exploited in a multiprogramming environment for enhanced system throughput. The independence of user tasks belonging to a single job is exploited in a multitasking environment for enhanced personal throughput.
In batch mode, the operating system schedules independent user jobs for the processor resources. Jobs which wait for I/O or other reasons are rescheduled so that jobs which are ready to run may execute. This philosophy optimizes the utilization of the processor resources, and results in a system throughput speedup approaching the number of processors in the system.
A measure of the increase in system throughput is provided by the following example. Twenty copies of a vectorized program, each requiring 32.6 seconds of CPU time, are submitted simultaneously. The group of jobs represents a system workload of 652 seconds. If executed on a single XMP processor, the wall clock time is also 652 seconds. When two CPUs are used to simultaneously process the workload, the wall clock time, measured from when the first job starts execution until the last job completes execution, is now 328 seconds. The system throughput speedup is 652/328 = 1.99. See figure 14. To process the workload on four CPUs, the wall clock time is 171 seconds, for a system throughput speedup of 652/171 = 3.81.
Wall clock
Workload time (sec) Speedup
(sec) 2-CPU 4-CPU 2-CPU 4-CPU
652. 328. 171. 1.99 3.81
In certain applications, an execution speed which exceeds the capabilities of a single CRAY XMP processor is necessary. The multitasking abilities of the XMP enable the full power of the machine to be directed toward a timely solution of such large jobs. Multitasking can exploit the parallelism inherent in these codes from microscopic to macroscopic levels, and enhance either scalar or vector performance.
The benefits of multitasking are illustrated in figure 15 for several different application codes. PICF, a particle-in-cell program, is a scalar code which simulates the interaction of beams of plasma particles. See [11]. Independence occurs in the tracking of particles and the calculation of total charge distribution. The model experiment tracks 37,000 particles over 100 time steps. Ninety-seven percent of the total execution time of the program is spent in code which can be multitasked.
SPECTRAL is a short term weather forecasting code. The program is highly vectorizable. Here, independence occurs inside each time step at the outermost loop over latitudes. The model experiment has a global grid structure of 160 latitude and 192 longitude points, and simulates 200 time steps. Ninety-eight percent of the total execution time can be multitasked.
GAMTEB is a Monte Carlo code which transports gamma rays in a carbon cylinder. Parallelism occurs in the independent tracking of the original gamma rays and their offspring. This scalar program uses a technique [12] which allows reproducibility of results for codes whose execution flow is determined by a random number generator, irrespective of the number of tasks or processors. Multitasking accounts for 99 percent of the execution time of a model experiment involving one million original rays.
3DMIGR, was described earlier in the section on I/O performance speed up using SSD. Further speed up is obtained by exploiting the independence which occurs in the frequency domain at each depth level, after Fourier transformation over time. Multitasking is applicable to 98 percent of the total execution time of this highly vectorized code.
WILSON is a lattice gauge program for measuring the force between quarks[17]. The program uses a 3 subgroup pseudo-heat bath algorithm for lattice link updates, and a Wilson loop with Parisi improvement measurement algorithm applied every sweep. Parallelism occurs in the independent updating and measurement of lattice link values. Multitasking may be applied to 100 percent of the execution time of a production experiment involving a lattice of size 24×24×24×48 and 3500 sweeps.
AC3D is a seismic forward modelling code used to construct synthetic data by the solution of a 3-D wave equation [18]. The data are then compared to field results to determine a better model for the subsurface. A Fourier method is used which, because of its need for fewer grid points, is more efficient than a traditional finite-difference approach. Parallelism occurs in integrating independent spatial planes with FFTs. Multitasking accounts for 98 percent of the execution time of a 256×256×256 size model with 1000 time steps.
ARC3D is a Reynolds-Averaged Navier-Stokes aerodynamics code using an implicit approximation algorithm [19]. Parallelism is exploited in processing independent grid planes. Multitasking is used in 99 percent of the execution time of a model experiment having a 30×30×30 grid with 100 time steps.
HESS is a two-dimensional GaAs HEMT device simulation program for measuring steady-state current-voltage characteristics [20]. At each time step, the program solves a Poisson equation for the new potential, and uses an explicit scheme to update current and energy flux, electron concentration, and average energy. Parallelism occurs within each time step in the red/black SOR Poisson solution algorithm, and in the natural independence found in explicit schemes. Multitasking accounts for 99 percent of the execution time of a production experiment involving a 192×43 grid and 60000 time steps.
For each program, the maximum theoretical speedup attainable with no overhead may be computed. Let t1 be the single CPU execution time. Then the highest speedup possible for p processors is given by
Sp = (t1) / ( t1 * ( (1. - f) +(f / p) ) )
where f (the degree of parallelism) which is multitaskable.
Program 1-CPU 2-CPU 4-CPU
Execution time
PICF 72.3 sec 37.9 sec 20.7 sec
SPECTRAL 333.7 sec 174.4 sec 94.0 sec
GAMTEB 202.0 sec 103.0 sec 53.8 sec
3DMICR 3.49 hr 1.85 hr 1.01 hr
WILSON 7.65 days n/a 2.03 days
AC3D 4.6 hr n/a 1.3 hr
ARC3D 103.0 sec 55.0 sec 29.5 sec
HESS 3.50 hr 1.81 hr 0.97 hr
Actual Speedup (Theoretical Speedup)
PICF 1.00 1.91 (1.94) 3.48 (3.67)
SPECTRAL 1.00 1.91 (1.96) 3.55 (3.77)
GAMTEB l.00 1.96 (1.98) 3.75 (3.88)
3DMICR 1.00 1.89 (1.97) 3.15 (3.85)
WILSON 1.00 n/a 3.77 (4.00)
AC3D 1.00 n/a 3.50 (3.80)
ARC3D 1.00 1.87 (1.98) 3.50 (3.86)
HESS 1.00 1.93 (1.98) 3.67 (3.88)
Maximum theoretical speedup based on degree
of parallelism is given in parentheses.
The recorded speedups for these codes result from a combination of high percentage of parallelism, large granularity of tasks, and low synchronization overhead in the hardware and software. Other application codes will produce multi-tasking speedups which vary depending on the independence exploited and the multitasking programming style and mechanisms used.
The introduction of the CRAY XMP has set a new standard for high speed and large scale scientific computation. Its balanced and flexible architectural design, both in hardware and software, addresses the computational and I/O requirements of user programs , thus meeting the user need to solve larger and more sophisticated application problems.
Additionally, it has set a new direction for supercomputing. With its multiple vector processors, it can simultaneously exploit two dimensions of parallelism, and, with its unsurpassed I/O capabilities, can be used in many application areas to solve problems which previously could not have been attempted.
1. Srini, Vason P., and Asenjo, Jorge F., "Analysis of CRAY-lS Architecture," Proc. of the 10th Annual International Symp. on Computer Architecture, IEEE & ACM, 1983, pp. 194-206.
2. Hockney, R. W., and Jesshope, C. R., Parallel Computers, Adam Hilger Ltd., Bristol, 1981, pp. 69-95.
3. Johnson, Paul M., "An Introduction to Vector Processing," Computer Design, February 1978, pp. 89-97.
4. Kozdrowicki, Edward W., and Theis, Douglas J., "Second Generation of Vector Supercomputers," IEEE Computer, Vol. 14, No. 11, Nov. 1980, pp. 71-83.
5. The CRAY-1 Computer Systems, Cray Research, Inc., Pub. No. 22400088.
6. Worlton, Jack, "The Philosophy Behind the Machines," Conference on High-Speed Computing, Glenden Beach, Or., 1981, sponsored by Los Alamos and Lawrence Livermore National Labs.
7. Bucher, Ingrid Y., "The Computational Speed of Supercomputers," Proceedings of SIGMETRICS, 1983.
8. Worlton, Jack, "Understanding Supercomputer Benchmarks," Los Alamos Internal Report, March, 1984.
9. Larson, John L. "Multitasking on the CRAY XMP-2 Multiprocessor," IEEE Computer, Vol. 17, No. 7, July 1984.
10. Hsiung, Christopher C., and Butscher, Werner, "A Numerical Seismic 3-D Migration Model for Vector Multiprocessors," Parallel Computing, Vol. 1, No. 2, December 1984, pp. 113-120.
11. Hiromoto, Robert, "Results of Parallel Processing a Large Scientific Problem on a Commercially Available Multiple-Processor Computer System," Proceedings of the 1982 International Conference on Parallel Processing, IEEE Computer Society Press, August 1982, pp. 243-244.
12. Frederickson, Paul, Hiromoto , Robert, and Larson, John, "A Parallel Monte Carlo Transport Algorithm Using a Pseudo-Random Tree to Guarantee Reproducibility," Los Alamos National Laboratory Report LA-UR-85-3184, submitted for publication in the Journal of Parallel Computing.
13. Kncis, Wilford, Industrial Real Time FORTRAN Standard, SIGPLAN Notices. July 1981, pp. 45-60.
14. Chen, Steve S., "Large-scale and High-speed Multiprocessor System for Scientific Applications - CRAY XMP Series," Proc. NATO Advanced Research Workshop on High Speed Computation, J. Kowalik, ed., Springer Verlag, Munich, West Germany, June 1983.
15. Hwang, Kai , and Briggs, Faye, Computer Architecture and Parallel Processing, McGraw-Hill1, New York, 1984, pp. 714-731.
16. Multitasking User Guide, Cray Research, Inc., Publication SN-0222, January 1985.
17. de Forcrand , Philippe, and Larson, John, "Quantum Chromodynamics on the CRAY XMP/48 with SSD," Cray Channels, Winter 1985.
18. Edwards, Mickey, Hsiung, Christopher C. Koslof, Daniel D., and Reshef, Moshe', Three Dimensional Seismic Forward Modelling, Part 1: Acoustic Case." submitted to the Journal of Geophysics.
19. Barton, John T., and Hsiung, Christopher C.,"Multitasking the Code ARC3D," to appear in Proceedings of the GAMM Workshop, The Efficient Use of Vector Computers with Emphasis on Computational Fluid Dynamics, University of Kahlsruhe, West Germany, March 13-15, 1985.
20. Larson, John, Sameh, Ahmed, Isik, Hess, Karl, and Widiger, Dave, "Two-Dimensional Model or the HEMT: (A Comparison of Computation with a supermini and a Cray)," to appear in the Proceedings of the First Workshop on Large Scale Computational Device Modelling, NSF and IEEE Device Society, Naperville, Illinois, April 18-19, 1985.
