
MMI2 was a five year research project drawing on 60 man years of effort that started in January 1989 with funding from the CEC under the ESPRIT initiative. The consortium undertaking the project consisted of 2 software companies, 2 universities and 3 research laboratories; BIM (Belgium) as prime contractor, and Intelligent Software Solutions (Spain), University of Leeds (UK), Ecole des Mines de Saint-Etienne (France), Informatics (UK), ADR/CRISS (France), INRIA (France).
The objective of the project was to develop a highly interactive multi-modal interface for human-machine interaction with knowledge based systems. More specifically, the project aims to build a human-machine interface which will:
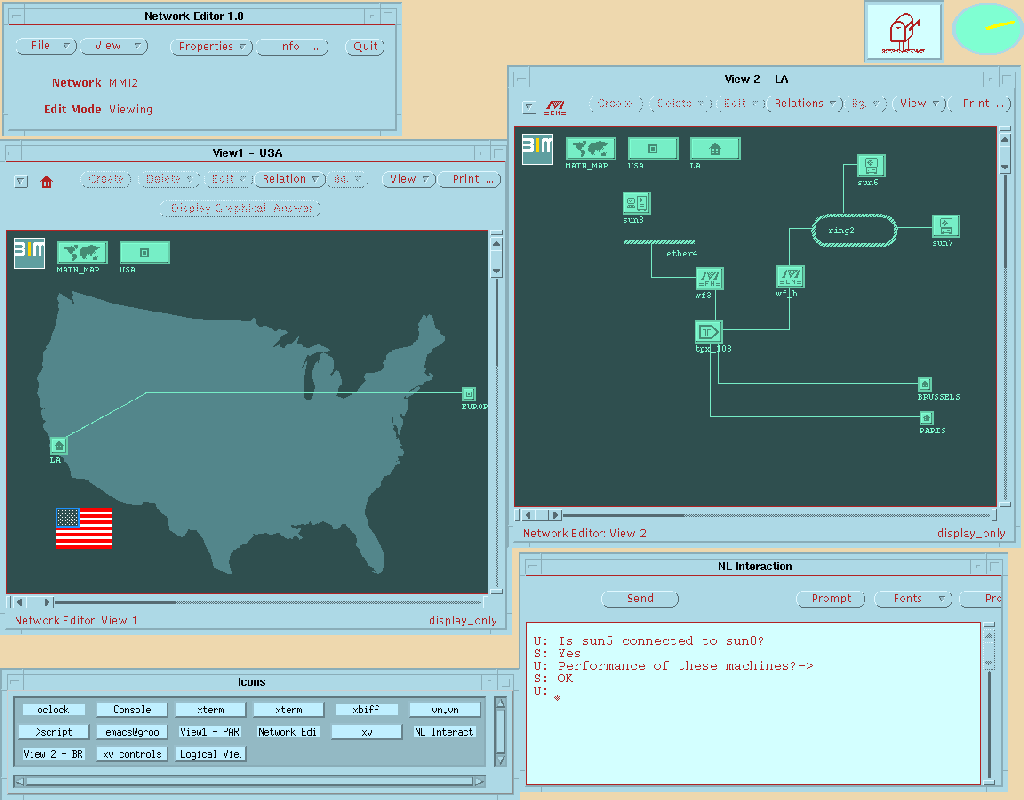
The interface provided simultaneous interactive use of modes suitable to support the developed skills of professional users, and natural communication modes well suited for naive users. These modes include: Natural Language typed at the keyboard (English, French and Spanish), Graphics with Direct Manipulation, Mouse Gesture, and Command Language.
The interface was initially developed to accommodate a Prolog based Knowledge based system for local and wide area computer network design. This provided the requirement for intelligent dialogue, different classes of users, and the integration of multiple modes of representation and communication. The interface was designed to be portable across a range of potential applications of knowledge based systems. Tools for the rapid adaptation of the interface were developed in the later stages of the project.
The overall architecture of the project was a three layer structure with the different interface modes represented by modules (or experts) in the upper layer. The central layer contained six experts to manage dialogue and the lower layer represented the application program. The six experts in the dialogue management layer could be imagined as being placed on the points of a pentagram with one in the centre. The central expert acted as a central switching facility to direct information packets between the other five dialogue management experts; the second communicated with the application; the third stored information about the state of the screen and user interface; the fourth constructed and managed a model of the user; the fifth managed the dialogue context; and the sixth managed the semantic information required to communicate between the user and the interface.
Prototype implementations of the major components of the system took place in the second year of the project to allow studies of their interaction to be undertaken. Informatics were involved in four tasks
The CMR was the language used to pass information between the experts in the overall architecture. It uses a typed first order logic that used promiscuous rectification of events and relations, augmented by communication forces. Expressions in this language were then put into packets along with details of the mode (Graphics, English etc) from which the information was derived, the time the packet was constructed and other information relevant to later processing.
The formal specification of the language was produced in 1989, although the details of the predicates which can be included in it, the cases of those predicates and the set of communication forces which are admissible were further developed later.
The architecture was implemented and stereotypical knowledge incorporated about users derived from experimental studies.
The architecture acquired information about the user, stored that information and provided it to other experts when required. Acquisition used three methods:
The information was stored in a network of stereotypes. The stereotypes at the top of the network represented general beliefs, goals, preferences and plans of most users. The stereotypes at the leaves of the network represented the individual users themselves. Between these were stereotypes of increasing specificity. If a belief was not explicitly represented in a user's own stereotype model, then the stereotypes up to the top of the network were successively searched to find that belief. If the belief, or a contradiction was not found, it was assumed that the user did not hold it since the model of the world was closed and that which was not explicitly stated as true was assumed to be false.
As beliefs were added to a user's model they were tested against beliefs in the stereotypes from which that user inherited information. If they contradicted any existing beliefs the stereotype which contained the contradictory stereotype was removed from the inheritable set. After information had been added to a user's model, and all contradictions removed, a list of rules was consulted to assess if the new set of information about the user implied that the user model should inherit information from stereotypes which it did not; and added them if appropriate. This process maintained the truth of the information about users by implementing a non-monotonic logic; although at a cost for run time efficiency.
The beliefs, goals, preferences of user's stored in user models, differentiated between knowledge, belief, and awareness. Logical closure under belief was not included since users clearly do not believe all the implications of any belief and often maintain not only beliefs whose implications are contradictory, but also explicitly contradictory beliefs.
The experiments to derive the stereotypical information about users and the content of the rules to assign stereotypes to user models were conducted by INRIA. The data from these experiments were analysed and incorporated into the implemented user model.
The architecture for the graphics mode was implemented by Informatics to allow CMR packets, produced by the system, which contained numeric information to be displayed to the user as histograms, pie charts and line graphs. Users could then alter or query values in these representations through direct manipulation, which would then result in CMR packets being sent to the rest of the system.
The graphical interface was developed further to investigate the semantics underlying the manipulation act of changing or referring to components of graphical displays. For example, if a user typed the English sentence Tell me more about <select> (where <select> is an act of selecting the title of a graph with a mouse) did the user wish to know about graph titles in general, or this one in particular, or is the user using the title of the graph as a symbol to refer to the body of information displayed on the graph? A knowledge base was developed which could automatically design layouts for graphs using the best principles from ergonomic and graphic design research.
Leeds University developed and implemented an algorithm for identifying design gestures of the class normally used to mark up manuscripts for editing when they are drawn on the screen using a mouse. Informatics developed the semantics of these design gestures so that the actions could be coded in CMR and transmitted to the rest of the system.
Just as the CMR was used to represent the meaning of user and system actions at the interface, so there needed to be a language to represent the knowledge about the domain within the application KBS. This representation needed to be sufficient to support the reasoning about the domain which the KBS itself will perform, and needed to allow the interface to interact with it in order to support co-operative dialogue and advanced explanation.
See also:
