
With the demise of SERC the EASE Programme and my Co-ordinator role now come under EPSRC (Engineering and Physical Sciences Research Council). There have also been structural changes in the management of activities. While the details of these are yet to be confirmed by the new Chief Executive of EPSRC, this has already resulted in the responsibility for my IT co-ordinatorship being transferred to the new Innovative Manufacturing Initiative (IMI). This will locate future engineering IT developments firmly in the most exciting and relevant area within the new EPSRC and bodes well for those who wish to undertake IT research, especially if that IT development relates to the new themes of the IMI. In the next ECN, when more is known, I will make you aware of the full implications of the change.
The important thing to report at this time is that we have decided to move the Engineering Decision Support Meeting from the 20-21 June to the 21-22 November. This will give me more time to take the new thinking from EPSRC into account in the detailed planning of this and subsequent meetings and ensure all interested researchers get to take part in the most appropriate way. Once again, for the next meeting, I would be particularly interested to hear from any researchers who have already produced decision support tools that are actually helping engineers' decision-making or IT systems which are usefully informing engineers. Those whose IT systems are actually being used by engineers "in earnest", are of particular interest to me, and I hope to you. If you are thinking of developing such IT tools also let me know, as your participation in the meeting is equally important, offering you the opportunity to meet others with similar plans. The November meeting will again be held at our London base at the Institution of Civil Engineers, so please put the new dates in your diary.
Finally, I would just like to remind you that my own base is moving from the 1st of April. By the time you read this I will be at the Graduate School, The Graduate College, Salford University, Manchester.
From 1 April 1994 Daresbury Laboratory and Rutherford Appleton Laboratory became a single entity under the name of DRAL (pronounced DeeRAL) and under the direction of Dr Paul Williams. The Head of Daresbury Laboratory is Dr Ron Newport and the Head of Rutherford Appleton Laboratory is Dr Gordon Walker. For an interim period of one year DRAL will be part of the Engineering and Physical Sciences Research Council, which will oversee the transition of DRAL to independent status.
Most supercomputer users are now faced with using highly parallel systems; because most, if not all, current supercomputers are highly parallel. To use any parallel system effectively, it is necessary to learn new programming techniques; as in the early days of vector computers, it is not (yet?) possible to leave everything to the compiler to sort out. But one difficulty in the way of wide acceptance of parallel machines, has been the difficulty of programming them. This has been especially true for Distributed Memory architectures, in which each processor has its own private memory. On these machines, processors communicate by passing messages; and the only programming paradigm available has been one in which the programmer writes code for each processor (in principle different code for each; more usually a common code for all save maybe a selected one or two) including the coding of data passing from processor to processor as required.
This has turned out to be much harder than writing serial code; and it is easy to give an example of why. Most scientific and engineering codes make heavy use of one and two dimensional arrays; let us add two vectors together:
DO I = 1,10000
a(i) = b(i) + c(i)
END DO
This is clearly a parallel operation; all the elements of b and c can be added in parallel. But for this to occur on a distributed memory machine, the elements of b, c, and hopefully a too must be distributed over the available processors. Who arranges that? The programmer; his code must deal with bits of vector on each processor, and he has to keep track of the bits.
Much better if the compiler would do that for you. Then your code could still refer to the complete vector or matrix object, and be much easier to write, understand, and maintain.
And that is what High Performance Fortran (HPF) does. It starts from the following premises:
c = a + band that is easier for a compiler, as well as a human, to understand)
To summarise:
High Performance Fortran is Fortran90 in which arrays are expected to be treated as distributed objects and array operations are expected to run as parallel operations. The user is expected to add compiler directives which guide the compiler in its task of distributing the arrays sensibly. The resulting code is portable across SIMD, MIMD shared memory, and MIMD Distributed Memory architectures (provided that they support HPF!) with DM architectures posing as usual the most difficult compilation problems.
Apart from compiler directives, HPF adds one or two new features (FORALL, several intrinsics, many new library routines) to Fortran90. It also defines a subset language (which includes both a subset of Fortran90 and a subset of the HPF directives) which is intended to be available earlier than the full language. This is not the place to give an exhaustive description of what is provided; instead we give a simple example to demonstrate the facilities:
REAL a(1000), b(1000), c(1000), x(500), y(0:501) !HPF$ PROCESSORS procs(10) !HPF$ DISTRIBUTE (BLOCK) ONTO procs :: a, b !HPF$ DISTRIBUTE (CYCLIC) ONTO procs :: c !HPF$ ALIGN x(i) WITH y(i+1) ........... a(:) = b(:) ! Statement 1 x(1:500) = y(2:501) ! Statement 2 a(:) = c(:) ! Statement 3 ...........
The lines starting !HPF$ are HPF directives; the rest are standard Fortran90, and carry out three array operations. What are the directives doing?
The PROCESSORS directive specifies a linear arrangement of 10 virtual processors; these will be mapped to the available physical processors by some way not specified by the language (but most early implementations might well demand that at least ten physical processors be available). Grids of processors in any number of dimensions (up to seven) can be defined; they should match the problem being solved, in some way - perhaps by helping to minimise communication costs.
The DISTRIBUTE directives tell (actually recommend to) the compiler how to distribute the elements of the arrays; arrays a, b will be distributed with blocks of 100 contiguous elements per processor, while c will be distributed so that for example c (1), c (11), c (21) ....are on processor procs(l) and so on.
Note that the distribution of the arrays x and y is not specified explicitly; but the way they are aligned to each other is specified. The ALIGN statement causes x (i) and y (i + 1) to be stored on the same processor for all values of i, regardless of the actual distribution (which will be chosen by the compiler: it will probably be BLOCK).
Now, how do these directives affect the efficiency of the code?
In Statement 1, the identical distribution of a and b ensures that for all i, a (i), b (i) are on the same processor. So this statement will not cause the compiler to generate any message passing.
In statement 2, there will again be no need for message passing; but if the ALIGN statement had lined up x(i) with y(i) rather than y(i + 1) there would certainly have been a need for communication needed for some values of i.
Statement 3 looks very like Statement 1; but the communications requirements are very different because of the different distribution of a and c. The array elements a (i), c (i) will be on the same processor for only 10% of the possible values of i, and hence for nearly all of the elements, communication of data between processors is needed; this was an unwise choice of distribution for c, if indeed this statement represented the bulk of the work. Clearly, a good choice of distribution and alignment can help efficiency greatly; and that is the point of having the directives. Equally clearly, it may not always be easy to choose the best distribution; if only because differing parts of the code may have differing "optimal distribution" requirements (the full HPF language allows distributions to be changed in mid-calculation).
And also equally clearly; it is much easier to write Fortran90 codes and embellish them with HPF directives, than to write the equivalent message passing code.
This example illustrates the steps taken in writing an HPF program:
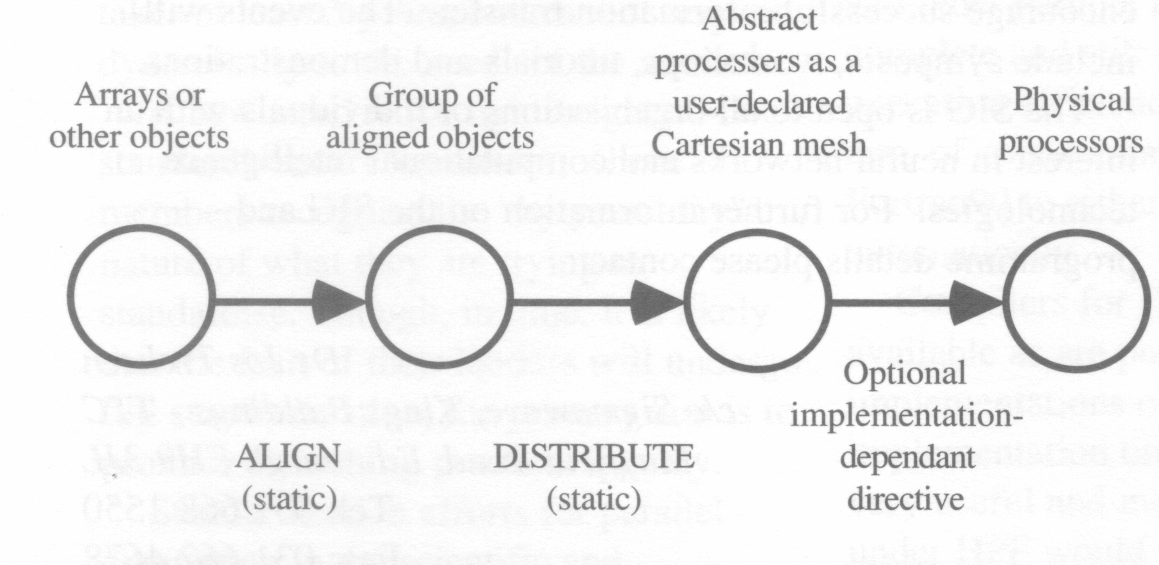
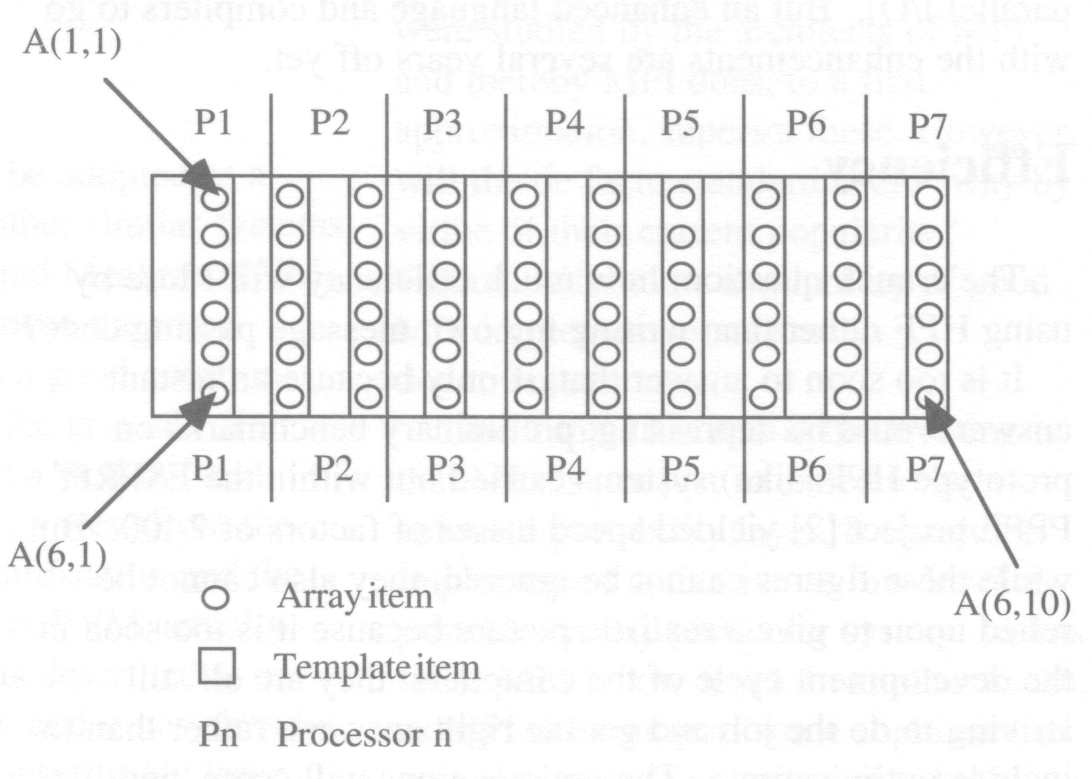
Here is an example in which a 2-D array is aligned with a 1-D template and distributed onto a 1-D processor chain:
Code:
!HPF$ PROCESSORS P(7) !HPF$ TEMPLATE T(20) INTEGER A(6,10) !HPF$ ALIGN A(*,K) WITH T(K*2) !HPF$ DISTRIBUTE T(BLOCK(3)) ONTO P
The resulting layout of A is shown in Figure 2:
Well, that depends on three factors; availability; versatility; and efficiency.
Availability
Most potential users have not yet seen a Fortran90 compiler, let alone an HPF compiler. But both are coming fast. Fortran90 is now available on many systems, with the NAG portable translator well established and production quality compilers on the IBM RS6000, Sun and other workstations (from EPC and NA Software), and (soon) on PCs and transputer arrays both T800 and T9000 [4]. Mainframe/Mini vendors are committed to produce compilers too, mainly this year.
There are also certain to be Subset HPF systems on the market in 1994, from NA Software [3]; the Portland Group; and probably others. That from NA Software is a translator from HPF to Fortran90 plus message-passing calls; so it will run on any system supporting Fortran90. It is due for beta release around September this year.
Versatility
It is indeed easy to write HPF programs; how versatile is the language? As a serial language, Fortran90 is very versatile indeed, with a level of facilities comparable to or better than C++. But the facilities for expressing parallelism in HPFI (the current language) are limited to data parallel applications; there is no explicit support for MIMD parallelism. This is less of a restriction than might at first be thought; after all, SIMD machines like the CM2, Maspar, and DAP have been used for a wide variety of applications. But it is a restriction. Perhaps worse, the support for sparse matrix manipulations is relatively poor; PDE applications with regular grids normally map well onto HPF, irregular grids less well.
There is an ongoing programme to develop HPF2, which will address these issues along with others (for example parallel I/O). But an enhanced language and compilers to go with the enhancements are several years off yet.
The crunch question; how much efficiency will I lose by using HPF rather than writing my own message passing code?
It is too soon to answer that, if only because an instant answer would be depressing; preliminary benchmarks on prototype HPF( -like) systems carried out within the ESPRIT PPPE project [2] yielded speed losses of factors of 2-100. But while these figures cannot be ignored, they also cannot be relied upon to give a realistic picture because it is too soon in the development cycle of the compilers; they are all still striving to do the job and get the right answers, rather than to include optimisations. The optimisations will come, and probably quickly; then a realistic benchmarking exercise can take place.
Efficiency will in practice depend heavily on the style of coding used. Current systems will work quite well on new Fortran90 codes making full use of array facilities. They will have trouble getting efficiency from existing, or even "mildly converted", Fortran77 codes. This is one reason why the efficiency tests in [2] were poor; the codes were converted from Fortran77, rather than written from scratch.
So, HPF is coming and HPF is attractive. But it is a little too soon to put all of your eggs into the HPF basket, especially if you need to convert existing codes to run on a parallel machine; it is still safer to use explicit message passing for these. But new codes? Try HPF.
The author has to admit to being associated with both the Fortran90 and HPF compiler developments at NA Software, which have involved collaboration with the University of Liverpool; the views expressed here are doubtless coloured by this involvement, but are purely personal. Thanks are due to the many people involved in these projects for discussions over a long period which have helped form these views.
[1] High Performance Fortran Language Specification, Version 1.0 Technical Report, Rice University, May 1993
[2] Comparison of HPF-like Systems, V S Getov, T Brandes, B Chapman, A N Dunlop, A J G Hey and D J Pritchard, PPPE Working Paper, November 1993; to be published
[3] NA Software Ltd, HPF System User Guide and User Manual, 1994
[4] NA Software Ltd, Fortran90Plus compiler User Guide, 1994
Following the successful inaugural meeting held last year, the Special Interest Group (SIG) is now operational, and has commenced an ambitious and exciting programme of neural network events and activities. The Group currently has over 200 registrants, with 60% of these coming from industry, and the remainder from academia.
The Group will provide a local forum in Scotland for neural computing and computational intelligence technologies. The key aims of the Group are to facilitate successful technology transfer, foster collaborative projects, and to encourage the adoption of practical applications. The Group will not only be concerned with the technical aspects, but also the business, market and adoption perspectives of neural computing.
To accomplish these goals the SIG has initiated a programme covering topics of direct relevance to members' interests. The format for these events is designed to encourage successful information transfer. The events will include symposia, workshops, tutorials and demonstrations. The SIG is open to all organisations or individuals with an interest in neural networks and computational intelligence technologies. For further information on the SIG and programme details please contact me.
A battle is on but the war may already be over. Many software systems are competing to become the definitive way of passing messages on the communication network that interconnects the processors in a parallel computer. There is a new kid on the block called Message Passing Interface (MPI). What makes this kid different is that it threatens to pull rank, rather than get involved in a neighbourhood brawl with the old-timers. Will this succeed? I attended a two day European Message Passing Interface Workshop on 17-18 January in an attempt to find out.
The workshop was held at the INRIA Laboratory, at Sophia Antipolis in the South of France. The event itself marked a significant rite of passage for MPI: the first open discussions between the designers and the potential users of the system. MPI could have significant ramifications for the whole parallel community, even those who simply wish to gain the best performance from their application codes on parallel architectures.
Parallel machines hold great promise for computationally intensive commercial. scientific and engineering programs. However, in a rapidly evolving field, any decision to enter into parallel processing is associated with a great deal of risk. Which machine should I buy? How difficult will it be to port code to a parallel machine? How do I avoid becoming locked into one machine architecture?
Manufacturers and software developers have recognised the need for software compatibility. Standards are the key! However, official standardisation takes at least 5 years, and cannot respond dynamically to the needs of the market.
A new trend is for lightweight ad-hoc standardisation committees, whose members recognise the by yesterday nature of what they are trying to standardise. Though, in time, it is likely that the fruit of their labours will undergo full standardisation, the primary aim is to produce something practical quickly.
Standardisation efforts for parallel computing in the scientific and engineering fields have largely been based on High Performance Fortran (HPF) which is basically a set of annotations to Fortran90 specifying the decomposition of the program's data between a number of processors. However, realising HPF on the important distributed memory class of parallel machine (where the processors communicate by message passing) is not a trivial exercise. This is where MPI fits in. It describes a standard way of communicating between processors available from both FORTRAN and C.
Why should MPI be adopted as a standard instead of other similar systems such as Parallel Virtual Machine (PVM), which probably has been the most widely used? This is a good question. One could argue on the grounds of technical superiority; a well defined programming model; a view from the outset towards standardisation and the fact that the authors of PVM actually support MPI! PVM is described as an experimental system, and it has already gone through some unsettlingly large changes - though since Version 3 it has been more stable.
Both HPF and MPI encapsulate parallelism and so, though more complicated than Fortran on its own, they simplify the task of mapping Fortran on to a parallel machine. Instead of an automatic paralleliser for Fortran77 or a truly parallel language, there has been some kind of meeting in the middle. Whereas the programmer will have to learn something about HPF and/or MPI to use a parallel machine, they are clean, portable and implementable using current technology. There are two such standards because the convergence of distributed memory and other parallel architectures is not complete and still a subject of research if execution efficiency is required. A final aim, of course, may be to convert Fortran90 to either MPI or HPF automatically.
Compilers for HPF are already available as are public domain implementations of MPI. An HPF implementation on top of MPI would be very useful and mean that codes written under HPF would also be supported on message passing machines. It has to be admitted that the MPI standard is difficult to understand because of its great flexibility and all-embracing scope. HPF is possibly the simpler to understand, but both standard documents are still a challenging read!
There is a place for a message passing standard in parallel processing. This gap is currently being filled by de facto standards such as PVM and PARMACS. Many of these standards were studied by the architects of MPI and thereby MPI does, to a first approximation, superset these. However, will the de facto standards hold sway by virtue of their current popularity? Critical will be the availability of good MPI implementations and documentation.
One thing I learned at the meeting is that MPI is not just intended to be a software portability layer. It should be implemented native i.e. as low-level as possible on any particular system. In this sense MPI is low-level. In another sense, as MPI does support some sophisticated communication constructs, it is high level and a cut above most of the existing message passing systems. The power of MPI comes from the combination of the two; high-level functionality at high efficiency! The hardware capabilities of the latest high-performance communication subsystems (such as fast broadcasting) will not be exploited by software which only generates point-to-point messages. MPI possesses a rich set of more complex and so-called collective communication operations.
MPI does have heavyweight backing and an impeccable pedigree, with many of the big names in parallel processing supporting it. Look out for news of MPI2 (or whatever the next version is called) which should address the remaining functionality necessary for a complete parallel programming environment (principally process control).
For a fuller version of this article or further information contact me.
The World Transputer Congress '94 is being held in the Villa Erba, Cernobbio, Lake Como, Italy from 5-7 September 1994. The wide ranging Tutorial Programme will be held on the 3-4 September at the same location.
The Conference, Tutorials and Exhibition will offer delegates an opportunity to listen to and interact with leading individuals in the field of transputer-based parallel processing and see the latest parallel processing products, not exclusively transputer-based from the leading suppliers. The Keynote/Invited Speakers this year will include Professor David May FRS (Inmos), Professor G S Stiles (Utah State University), Professor Marzano (University of Rome) and Professor S Noguchi (Tohoku University, Japan). Up to 60 submitted papers from authors world-wide, covering applications, systems and theory, will be presented in a number of parallel streams.
The event is sponsored by The Transputer Consortium, SGS- Thomson, the Commission of the European Union (CEU) and the Italian Transputer User Group (ITUG) and organised by TTC in conjunction with SMAU.
The CEU sponsorship is in the form of an award through the Human Capital and Mobility (EuroConferences) Programme. This award will allow us to support the attendance of some 40 young European researchers at WTC '94 (see article at the bottom of this page). Please note there are significant discounts available on delegate fees for both the Conference and Tutorials if you register by 7 July.
Provisional Conference and Tutorial Programmes, Registration and Accommodation Booking Forms, and further information on WTC '94 can be obtained by contacting me.
Once again this year we are offering free exhibition space (approximately 2m x 1m) for academics to demonstrate their work with transputers and display posters. There will be an area set aside for these in the Conference and Exhibition Centre. The standard (i.e. free) provision will be one power point, a table and two chairs plus poster space. It may be possible to arrange for transportation of equipment to and from the exhibition.
Anyone interested in taking up this offer should contact me no later than Tuesday 31 May.
At the very successful WTC '93 in Aachen, Germany last year, 56 young researchers from all over the European Union (EU) were funded under the Commission's Human Capital and Mobility (EuroConferences) Programme, to attend the Conference, Exhibition and two day series of Tutorials. Financial help in the form of delegate fees, travel and accommodation costs were given.
Those young researchers were delighted that they had been given the opportunity to experience a major international conference, which otherwise they would not have been able to do. The general consensus was that WTC '93 was a very exciting event which all had benefited from attending.
It is expected that funds will be available again this year to enable young researchers to attend WTC '94 at the Villa Erba, Cernobbio, Lake Como, Italy.
Those eligible to apply for an award must be either i) citizens of an EU Member State or an EFTA country, apart from Switzerland, or ii) persons resident, and working in research for at least one year, in a EU Member State or an EFT A country, apart from Switzerland.
Generally, applicants should be under 35 years of age for men and 40 years of age for women. But what will be more important will be that applicants be post-graduates with their careers in the early stages of development. For information on the Conference and Tutorial Programmes together with a CEU Award Applications Form please contact Dr Susan Hilton. The deadline for return of Application Forms is 31 May 1994. Successful applicants will be notified by 16 June and they will be required to complete and return the appropriate registration forms by 13 July.
The Informatics Department of RAL was approached by the Administration Department to provide a system to semi-automate the Laboratory's recruitment process. A network of PCs offered the most cost-effective, timely and user-friendly solution, and provided us with the opportunity to explore the ease with which a highly distributed application for such machines could be created using readily-available software tools. A prime goal was to avoid the recruitment staff having to deal with computing issues whilst dealing with a large amount of data, so providing a state-of-the-art interface was an integral factor in the system design.
As a guide to the complexity of the system, the recruitment clerks have to deal with around 70 Vacancy Notices (VNs) simultaneously. Completing a VN requires around 400 tasks to be performed, with about 200 documents involved, subsets of which are duplicated for each applicant, interviewee, interview board member, and new employee.
The recruitment business case workflow has been captured in a semi-formal manner using a cue card stack metaphor. A series of cue cards represents the sequence of steps which must be carried out to fill a vacancy.
ROAr provides overview facilities to allow the progress of work within the group to be observed. The system can also gather statistics needed to comply with legal obligations and Laboratory policies. Summaries of each VN's progress are generated on a regular basis and e-mailed to the initiator.
ROAr will also support ad hoc queries from applicants or other interested parties.
The ROAr system architecture is based on a number of workstations for the staff with a central file server which may be Microsoft Workgroups, Windows NT, NetWare and/or NFS. The heart of ROAr is the Microsoft FoxPro relational database which provides swift access to detailed information about the status of current vacancies. The FoxPro development tools have been used to build basic data entry and browsing facilities. More complex graphical overview screens and the overarching application have been written using Visual Basic, and the two applications interact seamlessly via Direct Data Exchange (DDE). ROAr also integrates with other applications such as a diary system, e-mail system and word processor so that all essential tasks may be performed in context from within ROAr.
The system is already in use at the Laboratory and enhancements and multimedia features are planned for the future.
For more information contact me.
The formal specification language LOTOS is an ISO standard (ISO 8807) that has been developed to formalise and analyse modern information processing systems. LOTOS supports the analysis, specification, design and testing of such systems, complementing traditional development methods. LOTOS is one of a number of formal methods that are gaining acceptance for production of reliable and provably correct systems.
LOTOS is an acronym for Language Of Temporal Ordering of Systems. The name reflects the use of LOTOS to specify the behaviour of systems as orderings on events. For a simple telephone call, for example, the events occur in the order: dialling a number, making the connection, conversation, and either party breaking the connection. Of course, in realistic systems the range of events and the orders in which they may occur are much more complex. LOTOS provides a compact notation for specifying many kinds of behaviour, including sequential and parallel behaviour.
LOTOS stems from the work on specifying data communications standards such as those for Open Systems Interconnection (OSI). LOTOS has been used extensively to formally specify OSI standards. LOTOS is one of three Formal Description Techniques (FDTs) that have been internationally standardised for this kind of application.
However, LOTOS is not confined to data communications. It is a general-purpose language for specifying and analysing sequential, parallel or distributed systems. For example, it has also been used to model Open Distributed Processing (ODP), object-oriented approaches, digital logic, graphics standards, secure systems and neural networks. All of these pose major technical challenges that benefit from the use of a formal technique such as LOTOS.
LOTOS is the subject of a forthcoming course at City University, London, from 21-23 June 1994. The course will offer the opportunity for engineers to learn about formal methods through LOTOS, and to absorb theoretical and practical knowledge of LOTOS by using computerised tools on a variety of examples. More details of LOTOS and a copy of the course description may be obtained from me.
CFDS-FLOW3D is now available for use on the Atlas Cray YMP8. This is in addition to the other fluid dynamics software which are also available: Phoenics, FEAT, Star-CD, Fluent and NEKTON.
CFDS-FLOW3D from Computational Fluid Dynamic Services (CFDS) of AEA Technology is a general purpose CFD software package based on finite volume techniques. It can solve steady-state or time-dependent problems in two or three dimensions and incorporates compressibility, multiphase flows, combustion and turbulence (k-e, algebraic and full Reynolds stress) models.
Unstructured meshes can also be used: a stand-alone program called FEF3D takes a finite element mesh file and converts it to a CFDS-FLOW3D multi block mesh file, by automatically splitting the mesh into blocks. FEF3D will work on any finite element mesh of hexahedra (8 node bricks). It is also possible to use CFDS-FLOW3D with other mesh generators: PATRAN (from PDA), SOPHIA (from CFDS), I-IDEAS (from SDRC) and ICEM-CFD (from Control Data). Other features include a new post-processor with facilities including light shading, isosurfaces and interactive 3D streamline plots.
CFDS-FLOW3D may be accessed by any academic user although, as with the other CFD codes, a grant from a Research Council is necessary to provide the cpu time allocation needed to use the Cray. Anyone interested in pump priming, which is available for those who do not have a current grant, should contact me.
The main means of communication to all members of the CFDCC is via this newsletter, although information is occasionally distributed directly through the Club mailing list. If you do not return the reply paid card that is enclosed with this issue you will NOT continue to receive the ECN and will, therefore, not receive information about the Club's activities.
Following the success of this workshop, which was run for the first time last year (see ECN46, September 1993 for reviews), we will be holding the event again on 6-7 July 1994 at the Rutherford Appleton Laboratory.
The first day of the workshop will cover the fundamentals of good programming practices including testing, portability and structured programming. It will go on to cover those aspects of software engineering which are necessary to understanding how the commercial software Quality Assurances packages work, including static/dynamic analysis and metrics. In the afternoon three commercial vendors will demonstrate their codes. Also included will be a talk on Fortran90 by our guest speaker, Dr John Reid, and a presentation on the public domain tools which are available.
On the second day of the workshop, participants will have the chance to try each of the vendor codes and the public domain software on their own Fortran programs. This will be a whole day of intensive hands-on workshops carried out on a set of networked Sun Sparcstations.
Accommodation will be available at the Cosener's House on the banks of the River Thames in Abingdon.
As the workshop is limited on numbers due to availability of workstations, anyone wishing to attend should complete and return the registration form enclosed with this issue as soon as possible.
Do you organise a course covering any aspects of CFD? If so, we want to hear from you.
The CFDCC is collecting information about all the CFD courses being offered in the UK. The information will be used in two ways:
If you would like to benefit from free publicity for your courses then apply to me for a questionnaire.
The Steering Group for the Parallel Processing in Engineering Community Club (PPECC) has now been formed under the Chairmanship of Dr Brian Hoyle (University of Leeds).
The initial membership, representing Committees with an active interest in parallel processing, is as follows:
Further representatives from other engineering disciplines and from industry are expected to join soon.
The Steering Group held its first meeting on 11 April 1994 at which plans were agreed for the PPECC Programme for 1994/1995. Full details will be reported at the Inaugural Meeting of the Community Club to be held on 1 June 1994.
The Inaugural Meeting of the Parallel Processing in Engineering Community Club (PPECC) will be held on Wednesday 1 June 1994 at RAL.
The programme will include news on future Club activities and a number of keynote presentations on the use of parallel processing in different engineering areas. The results of the questionnaire sent to members (120 returns to date) will also be presented, and there will be an opportunity to express your views on how the Club can best meet your needs.

A registration form with details of the programme is enclosed with this issue. Further copies of this form (email or paper version) can be obtained from the PPECC contact. Exceptionally there will be no charge for attending this event.
For more information about any aspect of the PPECC's activities please contact me.
A good description of the activities of the Visualization Community Club is provided in its 1993 Annual Report which is available:
The 2nd Annual Report of the EASE Visualization Community Club, R Popovic (RAL), J Gallop (RAL), and K Brodlie (University of Leeds and Chair of the Community Club): (reference RAL-94-024).
In 1993, the topics of interest to the Community Club included visualization in electromechanical engineering research, animation and video, and the use of 3D in visualization. In 1994, the Community Club's activities will also include visualization in building research, visualization of experimental data and an increasing interest in using multimedia (by network and by CD) to disseminate examples, news and principles of visualization.
More about these and other activities can be found in the annual report, which also contains some pictures from work in the UK research community on: the application of an integrated design environment to heart valve design; data from testing a wind tunnel probe (a Community Club case study); the behaviour of chemical mixing experiments; and examples from participants attending the postgraduate course on Graphics and Visualization: Methods and Tools held at the University of Leeds, instigated by the Advisory Group on Computer Graphics (AGOCG) and the Community Club.
Members of the Community Club (now over 300) will have received this report automatically, by the time this newsletter has been distributed. Anyone wishing to have a copy and/or join the Community Club, please contact me.
A number of meetings under the EASE Programme of Events have now been fixed (see below). There will be 21 events in total, two having been held already, in the complete Programme. I will let you have more information as it becomes available. Four meetings will be run under the Information Technology Awareness in Engineering Initiative co-ordinated by Professor James Powell of Salford University, and the remainder run under the three EASE Community Clubs; Computational Fluid Dynamics, Visualization and Parallel Processing in Engineering.
We have been directed by the Engineering and Physical Sciences Research Council (with the support of all the relevant Committees of the Science and Engineering Research Council's Engineering Board prior to 1 April 1994) to instigate a policy of charging for EASE events as follows:-
| Venue | ||
|---|---|---|
| London £ (per day) |
Elsewhere £ (per day) |
|
| Academics | 50 | 40 |
| Industrials | 100 | 80 |
Where the course has a hands-on element the following daily costings will apply:-
| Venue | ||
|---|---|---|
| London £ (per day) |
Elsewhere £ (per day) |
|
| Academics | 125 | 100 |
| Industrials | 250 | 200 |
Registration Fees will not be applied to applications from those who hold a SERC or EPSRC Research Studentship, including CASE A wards. All other research students will be charged the academic fees as per the above tables.
Any income generated will be fed back to enhance the Programme. Although, in the main, attendance at EASE events has in the past been free of charge to academics, we are sure you will agree that the fees we have been asked to apply are very competitive when compared with those of other, particularly commercial, organisations. In the light of changing Government policy to funding higher education, attitudes must change.
We have already run a highly successful event under the new charging system as part of the IT Awareness in Engineering Initiative. Judging from this event, where there was no decrease in the numbers of people attending when compared with earlier meetings where no registration fee was charged to academics (150 applicants for 106 places on day I and 91 applications for 60 places on day 2); if the EASE events cover hot topics, then the community is able to find the funding to attend. The CFD Community Club seminar held on 20 April on Aerodynamics was also very successful attracting 80 people. One positive effect of charging is that it reduces the numbers of no shows.
| Date | Affiliation | Event | Venue |
|---|---|---|---|
| 1994 | |||
| 1 June | PPE CC | Inaugural Meeting | RAL |
| 6-7 July | CFD CC | Improving the Quality of Fortran Programs | RAL |
| 13-14 July | PPE CC | Parallel FORTRAN for Engineers Course | RAL |
| Autumn | PPE CC | Course on Parallel Processing Techniques | RAL |
| Late September | VIS CC | Visualization in Building Environments | University of Leicester |
| Autumn | CFD CC | CFD Applications using Parallel Architectures | Scotland |
| 21-22 November | ITEI | Engineering Decision Support Workshop | Institute of Civil Engineers, London |
| Early December | ITEI | Virtual Reality Seminar | University of Salford |
| 1995 | |||
| 9-13 January | CFD CC | Introductory CFD School | Cosener's House, Abingdon |
| January | CFD CC | Joint Meeting with MODAGCFM | University of Surrey |


A full report of the Workshop and its recommendations will appear in the July issue of the ECN.
In Figure 1 from left to right:
In Figure 2, delegates at the Neural Networks meeting at the Institute of Civil Engineers, London.
Copies of the Proceedings of the meeting held on 18th and 19th April 1994 under the EASE IT Awareness in Engineering Initiative are available at the cost of £25 each.
