

It is appropriate at this time of year to look back briefly at some of the events of 1989; a year which saw several developments at the Atlas Centre which we hope will be of benefit to our users.
The most substantial development, the upgrading of the 3090 to a model 600E with six vector facilities via the Joint Study Agreement with IBM, has enlarged the scope for high performance computing using vector, parallel and large-memory techniques. The strategic user programme associated with the Study Agreement is launched and substantial additional capacity has become available for peer reviewed computation.
Other developments include the provision of a new VAX front end for the Cray, the introduction of facilities for producing videotape output from the Cray and IBM (or in principle from other machines on Janet), and the introduction of VM/XA on the IBM service which was done under the auspices of an IBM Early Support Programme. By the time you read this we should have installed an automated tape cartridge handling system (see the article by John Barlow).
The Cray X-MP/48 itself has not been changed during the year, though its operating system has moved forward through one release level. The Cray is heavily loaded and the throughput for some of the largest projects is less than we would like. We hope to obtain some relief by enhancing the memory and other facilities in the next year, but this is the subject of bids for additional funding on which we have yet to hear the outcome.
As readers of issue 5 of FLAGSHIP will know, this year is the twenty fifth anniversary of the arrival of the Ferranti Atlas 1 computer in these buildings. There is obviously vastly more computational power available now than there was in the mid 1960s and the techniques and range of applications to exploit it have moved forward tremendously. But there is also an interesting continuity in many applications, and in the identity of some of the user groups, as ever more complex phenomena in certain disciplines become amenable to study via computational techniques. Computational science is now fulfilling its promise as a complementary technique to theory and experiment in the understanding of complex systems, whether natural or man-made, but there remain many problems for which present day computational power can only scratch the surface. While it is fruitless to speculate in any detail on what the next twenty five years might bring, it does seem that there are grounds for optimism that computational technology can continue its rapid advance for the foreseeable future through a variety of techniques and technologies.
On behalf of the staff at the Atlas Centre I would like to send the season's greetings to all our users and very best wishes for 1990.
For some time it has appeared to us that the workload on the Cray X-MP/48 has been reaching capacity in terms of deteriorating turnaround for moderately large jobs. The simple statistic of high priority/reserve time is misleading in this context because it implies that the Cray X-MP /48 is less than 70% full. It is somewhat difficult to analyse the situation in a machine where there is competition from a variety of jobs for both memory, CPU and in some cases SSD, but we have made the following analysis of the capability to run additional work:
We assume that an additional high priority job can be run only if there is both memory and a CPU available, and initially we ignore the SSD restriction.
Every hour the job state of the X-MP is sampled and the memory and CPU situation for high priority jobs is recorded. For a given memory size we can then say whether or not an extra job could be run. The sampling is over one week and we show the percentage of time that an additional job of different memory requirements would fit in. The conclusion is shown graphically in the Figure.
For job sizes of around 2 MWords there is clearly extra capacity in the machine in line with the high priority/reserve priority usage, but for 3 MWords or more the extra capacity available is small and new grant awards for large memory jobs will only get their work done at the cost of reduced throughput for other jobs. Queuing theory suggests that the last 10% of available time can be delivered only at the cost of very poor turnaround.
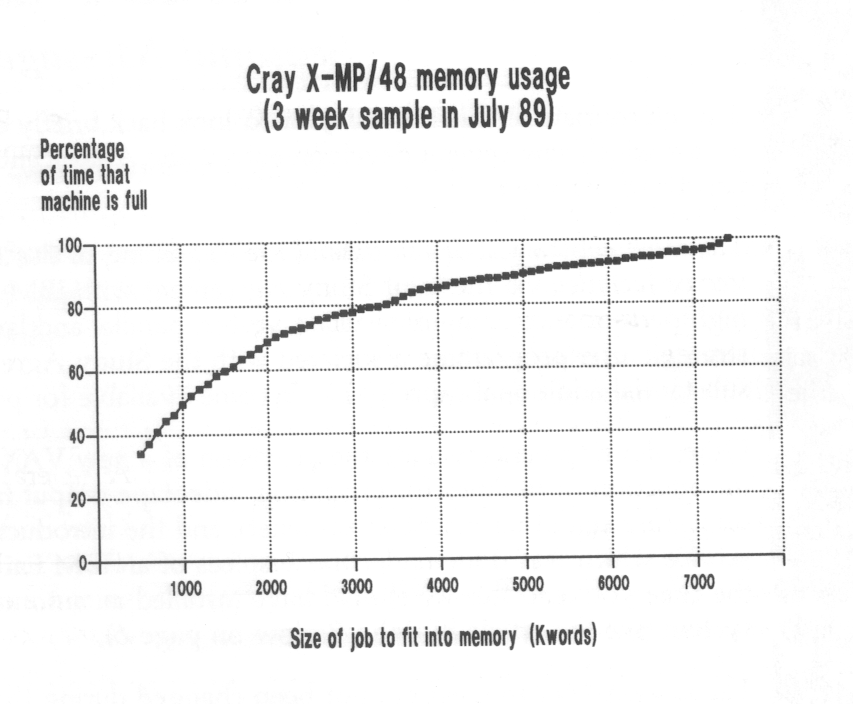
The problem as we all know is that the Cray X-MP/48 is under-resourced for memory and for various reasons users find difficulty in exploiting multi-tasking. It would be interesting to hear from users as to whether they would like to run jobs of larger memory size, and if so whether they are deterred by poor turnaround or by the extra charge factor for single task large jobs.
We would like to take this opportunity to remind all SERC funded users that it is perfectly possible to transfer part or all of a Cray grant to the RAL IBM 3090/600E which is much better provided with memory, even though it is not as fast in peak vector performance as the Cray X-MP. A suitable factor can be applied to allocations moved between the Cray and the IBM and for large jobs you may well find that the IBM gives a better turnaround time.
If you want to follow up this possibility please contact Roger Evans.
The Joint Policy Committee on National Facilities for Advanced Research Computing has recently established a sub-group, under the chairmanship of Professor P G Burke, to advise on matters relating to National Centre supercomputer resources and allocations. One of the topics covered in the initial meeting of this sub-group was the problem of persuading prospective users to apply for a realistic amount of computer resource and not to rely on obtaining a significantly larger amount of time than requested from the rapidly diminishing spare resource (Reserve Priority time, sometimes referred to as PO time).
It was recommended that the amount of computing that any project on the National Centres Supercomputers could use, be limited to a maximum of 150% of the time awarded (ie. the project's allocation plus a maximum of 50% overuse from any spare resource).
We are expecting that the Joint Policy Committee will endorse this recommendation and all three National Centres are currently making provisional plans to implement this limit as from August 1990. When the limit is introduced it will apply to both new and existing projects. It is hoped that this article will serve as an early warning to users with projects that may be affected by this limit and allow them time to reschedule work and apply for further resources if necessary.
Finally, it must be emphasised that, as national supercomputer resources become fully allocated, it will become increasingly difficult for projects to achieve any significant overuse. It is essential that grant applicants make every effort to provide a realistic estimate of the supercomputer resources needed by their project, both to ensure that the project can be successfully completed and also to permit the accurate assessment of future demand for national supercomputer resource.

A contract has been placed with StorageTek for the supply and delivery of a StorageTek Model 4400 Automated Cartridge System. It is expected that installation at the Atlas Centre will take place in November hopefully at about the same time that this issue of FLAGSHIP appears.
The Automated Cartridge System (ACS) is an information storage system that handles the movement of 18 track magnetic tape cartridges into and out of a storage module and mounts and demounts the cartridges on a StorageTek 4480 tape subsystem - all totally automatically. The StorageTek 4480 system is fully compatible with IBM's 3480 system. These 3480 tape cartridges are rapidly becoming an industry standard as a tape storage medium. The ACS will be coupled to the Atlas Centre's Cray X-MP/48 and IBM 3090-600E supercomputers and will bring a significant level of automation to the handling of magnetic tapes.
The ACS contains a robot that picks up a cartridge from its storage cell and loads it into the cartridge reader. The picture shows the robot arm in action. Robots are of course not new to the Atlas Centre. The Masstor M860 system contains one and it has been in service at Atlas since 1983. The Masstor contains special tape cartridges that remain within the device and provide a backup/ archival i the computer system. The StorageTek is significantly different in that it uses the standard 3480 tape cartridge and has an input/ output port that allows the insertion and extraction of users' 3480 tape cartridges.
The ACS system to be installed will be able to store up to 5500 tape cartridges equivalent to a total storage capacity of over a TeraByte of data. The robot can retrieve a cartridge and move it to the drive unit on average in about 11 seconds. Data stored in an ACS can now be considered as Online data! Further storage modules can be added to the system according to the demand and of course subject to the availability of sufficient funding. Each unit so added would have its own robot and cartridges can be passed from robot to robot.
StorageTek have installed several hundred such systems at a wide variety of sites across the world covering activities in industry, banking etc. Other sites with StorageTek ACS systems in operation in the scientific field include the University of London Computer Centre, DESY and SLAC. More news about the ACS and in particular its mode of use at the Atlas Centre will be published in a future issue of FLAGSHIP.

The M860 is used as an extension to the disk filestore. Infrequently-used data is migrated to the M860 to release disk space for more active data. Data is automatically copied from the M860 to disk when required.
The purpose of backing up is to recover data lost after mishaps on disks or the M860 which are unrelated to its owner. A spin-off from this is recovery of data which has been inadvertently deleted or corrupted by its owner.
The total filestore is split between disk (data used during the previous day) and the M860 (less recently used data). There is some overlap - some data is both on disk and in the M860
Backup consists of short and long term backup -tapes. These are two circular series of 3480 cartridge tapes.
Changed and new data is written to the next short term tapes nightly. Minidisks which have not been accessed for two days are copied onto M860 volumes (the data remains on disk unless the space it occupies is required for more active data). Data not on any long term tape and not on the last 7 days of short term tapes is also written to short term tapes; these tapes cycle in 3 to 4 Data not currently on long term tapes and not changed for 4 weeks is written to long term tapes at the weekend. A second copy, not more than 4 weeks out of date, is also kept on the long term tapes; these tapes cycle in 1 to 2 years.
The whole filestore is maintained in the M860, and the currently in use and new datasets are also on disk. The COS archiver writes new and changed datasets to fresh M860 volumes each evening. It also recycles M860 volumes less than half full, compacting them onto fresh volumes. Only one copy of each dataset is maintained in the M860.
The FIREDUMP program dumps whole M860 volumes onto a circular series of 3480 cartridges. Each evening, all those M860 volumes written a whole (or zero) multiple of "N" (currently 20) days ago are written to the next cartridges. The FIREDUMP tapes cycle in several months.
The total filestore is split between disk (recently used datasets) and M860 archive volumes (datasets not used for many days).
The disk datasets are backed up by fullpack dumps of real disk volumes. Each volume is dumped once per week; the cycle is two weeks long. Every night, new and changed datasets are backed up to tape. These backups remain available for 20 days.
Once a week, datasets on the "STORAGE" disks, which have not been used for 15 days or more and those on the "TRAN" disks which have not been used for 10 days or more, are archived to the M860 and delete from the disks. Archived "TRAN" datasets are deleted after 40 days. Only the most recent archived version of the "STORAGE" or "SECURE" dataset is held, any previous one is delete.
Currently archived MVS datasets are only held for 12 months. Every quarter, users with such datasets on the archive are warned that these copies will be deleted. There is no such deletion policy for CRAY or VM data, however we ask users not to abuse the system.
Users who have data which they know they will not require for many months, should copy it to tapes (3480s if possible) and not use the system backups for long term storage. It is expedient to make a duplicate copy of all tapes and store them in a different location to the originals.

Applying some simple techniques have allowed a FORTRAN program to run about 20 times faster. As some of these may be useful in other programs, the main steps taken are outlined below.
The application needs a lot of CPU time and its progress usefully monitored graphically. This led to an exercise in connecting a supercomputer (an IBM 3090 Vector Facility) to a Unix workstation (an IBM 6150). This is also described.
River simulations predict the behaviour of river networks under various flow conditions. The total river system may contain junctions, weirs, sluice-gates, reservoirs with water running in steady or unsteady state, confined or spilling out of the system. The results of the simulation may be used in the design of drainage, irrigation or flood alleviation schemes as well as water resource planning studies and catchment development planning.
The flow of water in an open channel in comparison to other fluid flow simulations is sometimes seen as a trivial problem. When considering the effect on the environment of a badly designed flood protection system or the wastage in a costly river diversion or training system involving several million pounds then doing a good simulation justifies itself. River simulations are carried out widely in the UK by the National River Authority.
A large river system can involve thousands of nodes and take several hours to run on a mainframe computer. It is a recent example of the application of vector processing to another new area.
On the connectivity side, displaying the changes of the key variables (water level, velocity, water flow) at a dedicated workstation as the simulation proceeds timestep by timestep on the batch mainframe improves the user's productivity and understanding of the river system.
Onda is a modern river simulation Fortran program used by several UK National River Authority regions. It is written and supported by the water division of the engineering consultancy, Sir William Halcrow and Partners, Swindon.
The open channel system consists of units delineated by nodes. The program reads characteristic data for every unit as well as the initial conditions for every node. The program then operates in a time- stepping mode during the computational phase. Its steering systems routes the computation through a set of subroutines appropriate to the physical units given in the data set. Each subroutine produces linearised equations describing the behaviour of a particular unit and the resultant set of equations is solved by a sparse matrix routine. Iteration is used to deal with non-linearities (about 6 iterations per timestep). The units currently available are as follows:
Onda and a medium-sized test case of 256 nodes was supplied for investigation into its potential for vectorisation. Work was carried out on the IBM 3090 at the Rutherford Atlas Centre. Within one man-month the program was shown to be vectorisable. It was first necessary, however, to perform considerable scalar optimisation. The program now performs around 19 times faster than in its original form on an IBM 3090.
The timings achieved for this test case are currently:
| CPU time | Ratio | |
|---|---|---|
| IBM 3090-180E (original) | 25 mins | 1 |
| IBM 3090-180E (best scalar) | 150 secs | 10 |
| IBM 3090-180E (best vector) | 80 secs | 19 |
For comparison, the program took 42 minutes on a Hitech-10 Whitechapel workstation, 87 minutes on an IBM 6150 Model 125 and over 600 minutes on a Sun 3/60 workstation.
The changes made to achieve these times are listed below.
This was trivial to implement but can have dramatic effects for sites (unlike Rutherford) that don't use OPT(2) or (3) as default. (Gain 950 seconds)
A hotspot analysis revealed that a large part of the CPU time was spent in a set of nested do loops involving complicated IF-THEN-ELSE constructs. These could readily be replaced with a table-look up algorithm. (Gain 195 seconds)
To save space, the simulation recalculated every timestep, several variables which were dependent only upon the geometry of the network. Many applications written in the days of small memory systems can be adapted to use more memory in order to improve execution speed. (Gain 150 seconds)
A function was called with eight arguments to return a logical true value if two lines crossed. This was replaced by a simpler, in-line test on whether two differences had the same sign. (Gain 32 seconds)
Divides are usually slower than multiply (perhaps by an order of magnitude) and X#*1.5 was found much slower than SQRT(X**3). At the same time some results, slow to calculate, were saved for later re-use and a call to a specialised exponentiation routine was replaced by inline code. (Gain 21 seconds)
Linear interpolation was performed for several functions over the same x range. By saving the x interpolation results, rescanning of the x range was avoided. (Gain 14 seconds)
The program uses the Harwell Library routine MA28. A vectorised version, MA48, is being developed by lan Duff of Harwell which takes advantage of matrix factorisation to reduce the calculation to several calls to the ESSL dense matrix solver routines. (Gain 40 seconds)
This involved reorganising the way nodes were referenced internally so that all units of a particular type were stored together. Node types occurring frequently were then processed together within one DO loop instead of one node per subroutine call. (Gain 21 seconds)
The IBM 6150 Unix workstation was already connected over the site Ethernet onto the IBM 3090 via the mainframe's 8232 adaptor. This was the way the workstation shared resources with the IBM 3090. By taking advantage of the TCP/IP software running under VM/XA on the mainframe, communication with the IBM 6150 was set up. Direct access to the mainframe could also be achieved using the 3278 emulation utility on the workstation.
Using NFS (Network File System) working under TCP/IP, a CMS minidisk was MOUNTed as an auxiliary device to the IBM 6150. The graphics program running on the IBM 6150 could then pick up and display data as it was being produced on the IBM 3090. It should also be possible to use X-Windows to run a graphics program on the IBM 3090 displaying data on the IBM 6150. Programs running on the two machines could also communicate with each other using the Remote Procedure Calls (RPC) facility.
The connectivity study was carried out by one of the authors, Francis Yeung of the Informatics Department at the Rutherford Laboratory. Because the program can also be parallelised, he is investigating adapting the program to run on a Transputer network connected to an IBM 6150.
Some general points can be drawn.
• Need for hotspot analysis.
Program optimisation cannot be achieved effectively without doing detailed execution time analysis. The VS Fortran Version 2
Interactive Debug provides detailed program timings.
• Vectorisation can only be effective on efficient scalar code.
The vectorisable content of this program was initially 7% and appeared inappropriate for running on a vector processor. After optimising the scalar component, the vector component became 70%. This is worth the effort of vectorising.
• Mainframes are good for program development.
One outcome of this project was a more efficient simulator for the workstation. Each test compile and run of the program on the workstation takes about 50 times longer than on the mainframe. The mainframe program development tools are very helpful.
• Workstations and mainframes work well together.
Using the number-crunching advantages of the mainframe in co-operation with the interactive capabilities of the Unix workstation introduces some very useful possibilities.
On October 27, the BBC Open University Production Unit spent the day filming in the Atlas Centre. They were completing one of the programmes in the OU's new oceanography course. In addition to regular filming (on video!) they were able to use the RAL Video Output Facility and the Silicon Graphics IRIS 3130 at Atlas to provide extra material for the programme.
Tony Jolly, producer of the series, wanted to have a sequence with a real oceanographer (in this case Peter Killworth from the Hooke Institute in Oxford) demonstrating the activity in the oceans that surround Antarctica. This is being modelled by the FRAM (Fine Resolution Antarctic Model) project on the Cray X-MP/48 at Atlas. FRAM already had display programs for their results.
By adapting the FRAM display program so that it ran on the Silicon Graphics Iris 3130, it was possible for Peter Killworth to demonstrate the model and then for the Iris to be switched so that it produced output suitable for direct recording onto videotape. (This is not possible on most high resolution displays). This output was put through part of the RAL Video Output Facility equipment and onto U-Matic SP tape, the same as the BBC were using for their filming.
In addition two animation sequences, too complex for even the Cray to produce in real time, were recorded in a "conventional" way by the RAL Video Output Facility - one is a display of the development of the currents over time and the other a transformation from a polar view of Antarctica to the Mercator projection preferred by oceanographers. The BBC are now finishing the editing of the new programme, which is due for a first showing on Saturday February 10 at 1:30pm on BBC2.
I would like to thank David Stevens of the University of East Anglia, Peter Killworth and Jeff Blundell of the University of Oxford and David Webb of IOS Wormley for their assistance in various aspects of this project.
In a computational context, the numerical modelling of three-dimensional sea regions consists of the solution of a set of partial differential equations (PDEs), subject to a set of initial and boundary conditions, for fields which describe the hydrodynamics and other physical phenomena of interest, as functions of time. Solution algorithms consist of the usual transformations of a continuum description to a discrete description by: finite differences; finite elements; functional expansions; or some combination of these (e.g., Davies (1980)).
The physical space is divided into three regions: sea, land and boundary. The fields are defined to be zero for all time on land. Therefore, because of the variety of sea geometries ("many" to "few" land areas with different spatial distributions), a general purpose program would incorporate at least two different data structures for an efficient implementation.
We have implemented a mixed explicit/implicit forward time integration scheme for an idealised sea to evaluate "vector multitasking" on the RAL Cray X-MP. The explicit component corresponds to a horizontal finite difference scheme and the implicit to a vertical functional expansion.
A set of conventions have been used, for program control and data scope that will enable any parallelism to be maintained as much as possible and hopefully increased, whenever the program is modified or extended. This is because the control and data storage dependencies are defined. These conventions are based on the OLYMPUS system described by Roberts (1974) and include a system of self documentation.
The conventions, along with the data structures we have identified, define our initial programming framework for a global organisation of data via COMMON blocks. This corresponds to the sharing of data between tasks. Changes to shared data are only made inside "critical sections", in which only one CPU executes.
Our current multitasking strategy, within the programming framework, is to adhere to the FORTRAN standard by the exclusive use of microtasking (Cray 1988). "Autotasking" (Cray 1989) is currently unavailable to us. This corresponds to a multitasking self-scheduling strategy. For example, different iterations of a DO loop are assigned at execution time to different CPUs. A CPU, when it has completed an iteration, will select the next uncompleted iteration. Therefore, each CPU may process a different number of iterations. For a number of iterations equal to an integer multiple of the number of CPUs with identical amounts of work, the workload is equally distributed amongst the CPUs and the program is said to be balanced.
We hope that these conventions and data structures will eventually evolve to form a set of multitasking conventions for the development, maintenance and extension of programs capable of effectively exploiting future generations of vector multiprocessors. We are motivated by the successful exploitation of multiprocessors in meteorological modelling (Dent (1986)).
The basic data organisation in our program is, of course, the array, for the storage of discrete field values. For arrays which store field values over the entire finite difference grid, we refer to a finite difference grid (FDG) data organisation, which is appropriate for a sea region where the amount of sea relative to land is large. For arrays which store field values only over the sea, land and boundary points on the finite difference grid, which participate in the computation of field finite differences, we refer to a packed participative point (PPP) data organisation, which is appropriate for a sea region where the amount of land relative to sea is large. The arrays are two-dimensional, for both FDG and PPP data organisations and are indexed by horizontal domain FDG and PPP indices, respectively, in the first dimension. In the second dimension indexing is by vertical domain functional expansion indices. This indexing is chosen for vectorisation over the horizontal domain and microtasking in the vertical domain.
The different access functions (e.g. sequential indexing with a mask, strip-mining and indirect addressing via index lists) that can be devised then define a set of data structures. The nature of the access function, in terms of its access patterns to the Cray X-MP's memory, determines the computational efficiency of a particular algorithm and data structure, for a fixed data organisation. Note that, an algorithm with its data dependencies can almost completely determine the data structure and the definition of computational efficiency can be extended to include the economies or charges of computation, communication and storage on a particular computer. That is, a program may be portable but its carefully designed computational efficiency may not be, because of differences in computer architectures and charging algorithms.
We consider the wind induced flow in a closed rectangular basin of dimensions 400 km in the x-direction, 800 km in the y-direction and a depth of 65 m, with a suddenly imposed and subsequently maintained horizontal wind stress of - 1.5 Pascal in the y-direction. The dimensions of the basin approximate the geometry of the North Sea. The finite difference grid has 225 points in the x-direction and 418 points in the y-direction, some of which, at the edges of the grid, represent the sea-model boundary. Since the basin is closed, flow field values for boundary points on the sea-model boundary are zero for all time, as are field values on land points on a closed sea-land boundary. The number of basis functions for the vertical representation of flow is 16. The time differencing is 30 s with 3200 forward time steps from the imposition of the wind stress.
This simple rectangular "North Sea Basin" with applied wind stress is used for the development of three-dimensional model mathematical and numerical formulations and represents a "benchmark" for the quality of model formulations and their computer implementations. Sufficient complexity is included in the physical description for an effective benchmarking of the data structures, which in addition, can include arbitrary land regions. In order to obtain reliable timings our definitive runs are all made in a dedicated "empty" machine.
In a batch environment, the availability of Cray X-MP CPUs is determined by the operating system's scheduling strategy (usually for maximum system throughput) and for a microtasking program, each CPU may be dedicated to the program for differing amounts of time. Therefore, in some cases a balanced program appears to be unbalanced, with some variation between identical program executions at different real times. For this reason our principal performance data is derived from program execution in a dedicated environment, to ensure reproducibility. Performance data from a single program execution in a batch environment, may be derived from a weighted mean of the metrics for each CPU, where the weights are the CPU times. This weighted mean may also be used for a program in a dedicated environment which is slightly unbalanced.
Our primary objectives are to maximise the program's throughput (the reciprocal of the elapsed real time in a batch or dedicated environment) and to minimise the memory requirement. These metrics usually determine a project's computer productivity and costs.
The throughput of a multitasking program in a dedicated environment can be estimated from Amdahl's law for the multitasking "speed-up" over a single task
S = n / (1 + s(n-l) + c),
where s is the fraction of sequential (scalar and vector) program processing time spent in critical sections, n is the number of CPUs used and c is a cost introduced by the use of multitasking. Note that the cost also includes the delays of imbalance and memory access conflicts (when a program is multitasking there are a number of CPUs competing for access to the shared central memory), as well as the multitasking overheads. The delays usually can only be measured, while the overheads can be estimated and measured. For example, for c = 0, we estimate the maximum FDG speed-up to be 3.35 for n = 4, and s = 0.065. (from single CPU measurements of the critical section of the masked FDG data structure). For n = 8 and 16, with the same fraction of critical section time, we have the respective maximum speed-ups of 5.50 and 8.10. This indicates that if computers, such as the Cray Y-MP series, evolve to 64 CPU machines, the development of new numerical formulations, with much smaller critical sections in the corresponding algorithms, will be necessary.
Measurement of program metrics on the Cray X-MP are by calls to the hardware performance monitor (Cray 1987). Our measurements are only of the program kernel which corresponds to 99.9% of the program's CPU time. To remove the possibility of perturbation, by program compilation, load, initialisation and I/O, we respectively start and stop measurement at the beginning and the end of the kernel execution.
Program metrics for execution in a dedicated environment on the RAL Cray X-MP are tabulated below.
Sea #1.
#boundary points = 1286
#grid points = 94050
Sea #2.
#land and boundary points = 43944
#grid points = 94050
Sea #1.
#boundary points = 1286
#grid points = 94050
Sea #2.
#land and boundary points = 43944
#grid points = 94050
The land distribution for Sea #2 is a central "diamond" shaped island with two smaller rectangular islands centred between the sea-model boundary and the central island on a basin diagonal. This peculiar sea is used to give varying distributions of vector lengths to simulate CPU-memory workloads of real seas.
MFlops are computed from a weighted mean as described in the text.
| #CPU | CPU time | Real time | MFlops | Speed-up |
|---|---|---|---|---|
| Sea #1. | ||||
| 1 | 1001 | 1001 | 176 | 1.00 |
| 2 | 1066 | 533 | 331 | 1.87 |
| 4 | 1268 | 318 | 555 | 3.15 |
| Sea #2. | ||||
| 1 | 1001 | 1001 | 176 | 1.00 |
| 2 | 1066 | 533 | 331 | 1.87 |
| 4 | 1263 | 326 | 558 | 3.07 |
| #CPU | CPU time | Real time | MFlops | Speed-up |
|---|---|---|---|---|
| Sea #1. | ||||
| 1 | 1494 | 1494 | 98 | 1.0 |
| 2 | 1664 | 832 | 176 | 1.80 |
| 4 | 2105 | 524 | 278 | 2.83 |
| Sea #2. | ||||
| 1 | 807 | 807 | 98 | 1.00 |
| 2 | 904 | 452 | 175 | 1.79 |
| 4 | 1147 | 288 | 277 | 2.82 |
The speed-ups agree well with our estimates from Amdahl's Law for the FDG data structure. The program is also well balanced, except for several seconds relative to the real time, in a few four CPU cases.
The FDG data structure is a trade-off of unnecessary work being done at a high computational rate (a low "communication" overhead because of the sequential addressing of memory banks) against more memory. That is, all field values are stored and computation occurs over land regions, but is masked to give zero field values. The PPP data structure is a trade-off of only doing necessary work at a lower computational rate (a high "communication" overhead because of the "random" indirect addressing of memory banks) against less memory. That is, only field values which participate in the computation of field finite differences are stored and computation only occurs over sea regions and the sea-land and sea-model boundaries.
Our hypothesis for the marked performance loss for four CPUs, is that the number of memory banks (thirty-two) on the RAL Cray X-MP is insufficient to support CPU-memory system communication when highly vectorised code is simultaneously executing in four CPUs. The X-MP/16 with sixty-four banks of memory is needed to provide enough memory bandwidth. We assume that the two CPU cases give a good measure of the multitasking overhead.
Nevertheless, multitasking with four CPUs is still worthwhile, since a program has approximately three times the throughput potential in a batch environment over a single CPU program. Also, if a program uses most, if not all, of the memory, multitasking becomes a social grace, as well as being "cheaper" in RAL Cray accounting units (the charging algorithm has a higher charge for a single CPU large memory (> 2 Mword) program than for a multitasking large memory program).
To test the above hypothesis, Cray Research (UK) Ltd. have kindly offered to benchmark our program on a Cray Y-MP series machine with at least 256 banks. A full account of our work (we have considered other data structures and program metrics) and a comparison with a Cray Y-MP will be produced elsewhere.
There are a number of motivations for multitasking large scale computational problems. Two are "financial" and "scientific". The financial motivation corresponds to the desire to utilise scarce and expensive resources effectively. The scientific motivation corresponds to the desire to maximise the quality and the quantity of science that be produced within the usual knowledge, resource and time constraints. Another motivation which can be said to combine the two above motivations is "competition". A research group who has invested in multitasking software development may enjoy a considerable advantage over a competing group who has not.
